先日投稿した、Azure VM で AD を使用しない AlwaysOn 可用性グループを Windows Server 2019 と SQL Server 2019 で構築する で、New high availability and disaster recovery benefits for SQL Server に触れました。
SQL Server 2019 では、SA の特典として、 DR 環境を Azure 上に構築することもサポートされており、これについては 新機能 のマトリクスにも記載されています。
(Failover servers for disaster recovery / Failover servers for disaster recovery in Azure が新しい特典となっていますので、Azure 以外でも DR 用のレプリカは得点を使用して作成できるはずです)

詳細な情報については、次の情報から確認することができます。
DR 環境については、次のように定義されています。
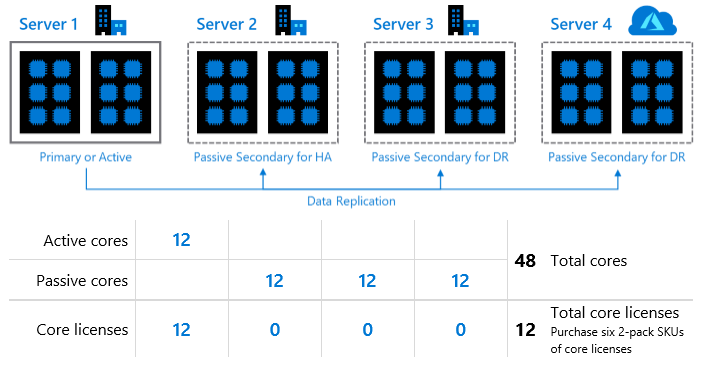
DR レプリカは、非同期レプリカのパッシブレプリカでありマニュアルフェールオーバーにより障害発生時に切り替えを行う環境であるとされています。
Disaster Recovery replica is defined as a passive replica setup as asynchronous replica with manual failover.
詳細については ライセンスガイド に記載されています。
A passive SQL Server replica is one that is not serving SQL Server data to clients or running active SQL Server workloads.
The passive failover instances can run on a separate server.
These may only be used to synchronize with the primary server and perform the following maintenance-related operations for the permitted passive fail-over Instances:
? Database consistency checks
? Log Back-ups
? Full Backups
? Monitoring resource usage data
Customer may also run primary and the corresponding disaster recovery replicas simultaneously for brief periods of disaster recovery testing every 90 days.
クライアントにアクティブなワークロードを提供することはできませんが、一部のメンテナンスに関連する作業については実施できる環境がパッシブレプリカとして定義されています。
DR レプリカを作成する際には、SQL Server の機能を用いて、データの複製を行うことになりますが、SQL Server のビジネス継続性を高めるための機能については ビジネス継続性とデータベースの復旧 – SQL Server で解説されているように、いくつかの機能を用いることが可能です。
同一ゾーン内の冗長構成については、同期レプリカで各レプリカが密結合となりますが、DR 用途のレプリカについては、遠隔地の DR 環境については疎結合で構築をしておいた方が、利便性が高いケースもあるのではないでしょうか。
そこで、今回は ログ配布 の構成を Azure Files を使用して実装したパターンをまとめてみたいと思います。
ログ配布は定期的にプライマリで取得されているバックアップを、セカンダリでリストアするという方式となり、AlwaysOn 可用性グループの同期レプリカと比較して、各環境には独立性があり疎結合なデータ同期環境として構築することができます。
今回の構成については、Windows Server 2019 の機能を使用していますので、使用可能な OS については限定されます。
なお、現時点で最新のバージョンである SQL Server 2019 では CU1 を適用しても、次のエラーが発生します。
セカンダリでログ配布のリストアは実施されるのですが、ファイルのコピーやリストア時に、メッセージの記録でエラーになり、次のようなエラーが出力されるという現象が発生します。
(エラーが発生することでメッセージが記録されなくなり、セカンダリ側の過去ファイルの削除が行われないという状況が発生します)
2020-01-26 19:39:15.16 ----- START OF TRANSACTION LOG RESTORE -----
2020-01-26 19:39:15.23 Starting transaction log restore. Secondary ID: '119eefbf-d7ad-49db-9a9c-894358d89154'
2020-01-26 19:39:15.24 *** Error: Could not log history/error message.(Microsoft.SqlServer.Management.LogShipping) ***
2020-01-26 19:39:15.24 *** Error: パラメーター値を SqlGuid から String に変換できませんでした。(System.Data) ***
2020-01-26 19:39:15.24 *** Error: オブジェクトは IConvertible を実装しなければなりません。(mscorlib) ***
2020-01-26 19:39:15.24 Retrieving restore settings. Secondary ID: '119eefbf-d7ad-49db-9a9c-894358d89154'
設定の妥当性を検証するため、2017 RTM でも試したのですが、2017 RTM では発生しませんでした。
SQL Server 2019 でログ配布を使用する場合は、既知の問題のようですので、以降の CU を待つとよいかと思います。
この問題は SQL Server 2019 CU2 で修正されているようですので、ログ配布を使用する場合は、CU2 の適用をお勧めします。
Read the rest of this entry »