チュートリアルで提供されているストリーミング処理はは、Scala で記述された「mssql-spark-lib-assembly-1.0.jar」なのですが、PySpark で書くとどうなるだろうと思って勉強がてら書いてみた際の内容です。
Microsoft の公式の技術文書ですと、Big Data Cluster に流用できる内容は、Azure HDInsight / Azure Databricks あたりになりますが、欲しい情報がなく、手探りでいろいろとやっていました。
Microsoft 関連のドキュメントとして、HDInsight Spark クラスターを使用して Azure SQL Database のデータを読み書きする あたりが今回の内容に近いのですが、
注意
現在、Spark から SQL Database へのデータのストリーミングは Scala と Java においてのみサポートされているので、この記事では、Spark (Scala) カーネルを使います。 SQL からの読み取りや SQL への書き込みは Python を使って行うこともできますが、この記事での一貫性を保つため、3 つの操作すべてに Scala を使います
と書かれているように、Scala を使用した例となっています。
Spark の勉強と、Python を使用した場合の情報を探すのに手間取り、書いたアプリケーションの内容の割には、とても時間がかかりました… orz
Big Data Cluster で使用可能なデータストア
SQL Server 2019 の新機能である「Big Data Cluster」 (BDC) では、Spark の実行基盤が含まれており、Big Data Cluster が利用可能なデータを Spark で処理 / 分析することが可能です。
Spark には、 Spark streaming の機能がありますので、「既に格納されているデータ」に対しての処理だけでなく、「データの収集」を行うことも可能です。
次の画像は、BDC の全体の構成となっています。
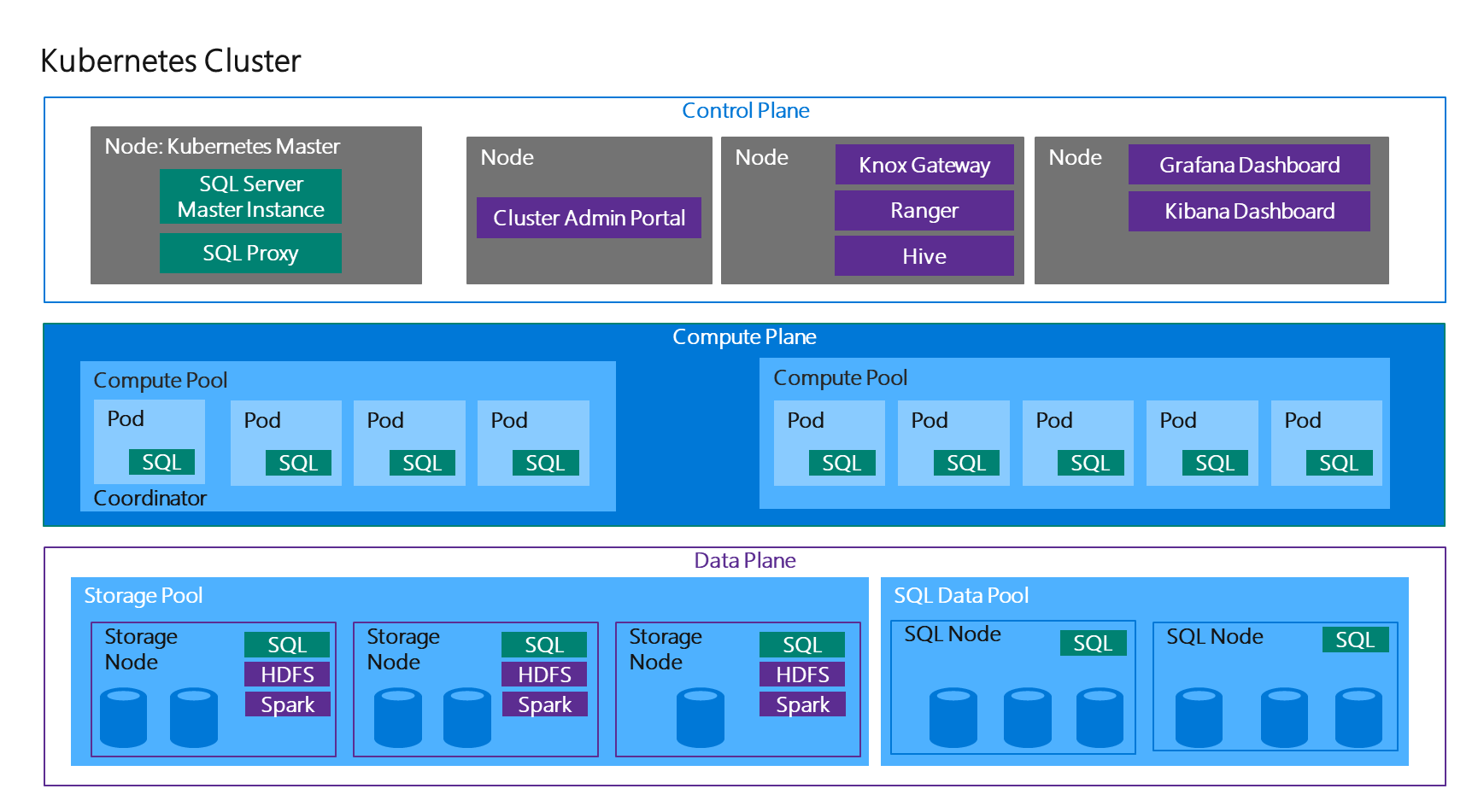
BDC は複数の Pod の組み合わせで構築されている環境で、様々なデータストアが内包された構成となっています。
標準で、次のようなデータストアを利用することができるようになっています。
- マスターインスタンスのデータベース
- BDC のデータを操作する際に T-SQL ベースで操作するときのインタフェースとなるインスタンス
- SQL Server on Linux のインスタンスであり、通常のインスタンスと同様に DB を作成できる
- ストレージプールの HDFS
- ストレージノードの Pod に作成される Hadoop HDFS の Data Node
- データプールのスケールアウトデータマート
- SQL ノードに作成されるシャーディングされたテーブルを格納できる SQL Server の DB
- Polybase を使用した外部データソース
- BDC 内のデータストアに格納されたデータではなく、外部データソースを Polybase によりアクセス
- HDFS 階層化
- CTP 2.3 時点では、BDC の HDFS に Azure Data Lake Storage Gen2 を HDFS にマウント可能
これらのデータストアにデータを格納する際には様々な方法をとることができ、標準的な方法については チュートリアル で解説されています。
Spark を使用することで、BDC でストリーミング処理を使用することもできます。
Big Data Cluster でストリーミング処理
CTP 2.3 時点では、標準で HDFS 上に配置されたファイルをストリーミング処理するためのアプリケーションが提供されています。
本投稿の冒頭で記載しましたが、チュートリアルでストリーミング処理が提供されており、HDFS 上のファイルであれば「mssql-spark-lib-assembly-1.0.jar」という、Scala で記述されたアプリケーションにより実行することができます。
PySpark でも同様の処理を実行してみたいなと思い、今回簡単ではありますが実装してみました。
初めて PySpark でドライバプログラムを組んだので、不要な処理入っていそうですが…。
ストリーミングで入力となったデータは、マスターインスタンスのデータベース内に格納されるようになっています。
マスターインスタンスの接続に使用するログイン / パスワードについては、引数化していないのでスクリプト内の外庁個所を直接書き換えてください m(_ _)m
CTP 2.3 時点の BDC では、マスターインスタンスのサーバー名と k8s のサービス名は固定だと思いますので、サーバー名については変更しなくても接続できるかと。
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
from pyspark.sql.types import *
conf = SparkConf()
conf.setAppName('RDD Streaming')
sc = SparkContext(conf=conf)
spark = SparkSession(sc)
ssc = StreamingContext(sc, 30)
distFile = ssc.textFileStream("hdfs:///streamdata")
def getSparkSessionInstance(sparkConf):
if ("sparkSessionSingletonInstance" not in globals()):
globals()["sparkSessionSingletonInstance"] = SparkSession .builder .config(conf=sparkConf) .getOrCreate()
return globals()["sparkSessionSingletonInstance"]
def saveRecord(rdd):
if not rdd.isEmpty():
rdd.first()
tagsheader = rdd.first()
header = sc.parallelize([tagsheader])
distData = rdd.subtract(header)
spark = getSparkSessionInstance(rdd.context.getConf())
distMap = distData.map(lambda line: ( int(line.split(",")[0]) if line.split(",")[0].isdigit() else None, int(line.split(",")[1]) if line.split(",")[1].isdigit() else None, int(line.split(",")[2]) if line.split(",")[2].isdigit() else None, int(line.split(",")[3]) if line.split(",")[3].isdigit() else None, int(line.split(",")[4]) if line.split(",")[4].isdigit() else None, int(line.split(",")[5]) if line.split(",")[5].isdigit() else None))
distMap.take(10)
schema = StructType([
StructField("wcs_click_date_sk", IntegerType(), True),
StructField("wcs_click_time_sk", IntegerType(), True),
StructField("wcs_sales_sk", IntegerType(), True),
StructField("wcs_item_sk", IntegerType(), True),
StructField("wcs_web_page_sk", IntegerType(), True),
StructField("wcs_user_sk", IntegerType(), True)
])
df = spark.createDataFrame(distMap, schema)
df.show()
df.write.format("jdbc") .option("url","jdbc:sqlserver://mssql-master-pool-0.service-master-pool:1433") .option("user", "<ログイン>") .option("password", "<ログインパスワード>") .option("database", "StreamDB") .option("dbtable", "streaminput") .mode("append") .save()
distFile.foreachRDD(saveRecord)
ssc.start()
ssc.awaitTermination()
ssc.stop()
sc.stop()
今回は、HDFS 上の「streamdata」というディレクトリをストリーミングの入力とし、そのディレクトリにファイルが配置された場合に「StreamDB」というデータベースにデータを格納するような処理を実装しています。
Spark では「Spakr Streaming」と「Structured Streaming」の 2 種類のストリーミング処理があるようで、「mssql-spark-lib-assembly-1.0.jar」では Structured Streaming が使用されています。
今回の PySpark でも Structured Streaming を使用して、mssql-spark-lib-assembly-1.0.jar を参考にした処理としたかったのですが、うまく実装することができませんでした…。
mssql-spark-lib-assembly-1.0.jar では、Structured Streaming で入力とした DatFrame を「foreach」で処理しています。
CTP 2.3 時点の BDC では、Spark は「2.3.0.27171」が使用されているようなのですが、PySpark で DataFrame の書き出しの foreach をサポートしたのが 2.4 以降のようでして、今回は Spark Streaming で処理を実装しています。
実行前の準備
実行する際には以下の準備をしてください。
最初に「streamdata」を HDFS 上に作成します。

次に、BDC のマスターインスタンスに作成し、「StreamDB」というデータベースを作成します。
テーブルについては、アプリケーション側で作成されますので事前に作成しておく必要はありません。

これで事前準備は完了ですのでアプリケーションを実行します。
今回は HDFS 上に配置した Python のスクリプトを Spark Job としてサブミットしています。
Spark Streaming は 30 秒単位で実行されるようにスクリプト内で設定しています。


これで準備は完了です。
データ投入
データについてはチュートリアルで使用している「web_clickstreams.csv」を使用しています。
このフォーマットのファイルを「streamdata」配下に格納します。

そうすると、30 秒単位のストリーミング処理で取り込み対象となり、StreamDB にテーブルの作成とデータの取り込みが行われます。

データを新たにアップロードした場合は、データの追加が行われますので、BDC の Spark で PySpark を使用した簡易のストリーミング処理のデモとして使用できるのではないでしょうか。