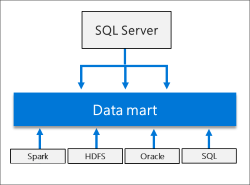
チュートリアルで提供されているストリーミング処理はは、Scala で記述された「mssql-spark-lib-assembly-1.0.jar」なのですが、PySpark で書くとどうなるだろうと思って勉強がてら書いてみた際の内容です。
Microsoft の公式の技術文書ですと、Big Data Cluster に流用できる内容は、Azure HDInsight / Azure Databricks あたりになりますが、欲しい情報がなく、手探りでいろいろとやっていました。
Microsoft 関連のドキュメントとして、HDInsight Spark クラスターを使用して Azure SQL Database のデータを読み書きする あたりが今回の内容に近いのですが、
注意
現在、Spark から SQL Database へのデータのストリーミングは Scala と Java においてのみサポートされているので、この記事では、Spark (Scala) カーネルを使います。 SQL からの読み取りや SQL への書き込みは Python を使って行うこともできますが、この記事での一貫性を保つため、3 つの操作すべてに Scala を使います
と書かれているように、Scala を使用した例となっています。
Spark の勉強と、Python を使用した場合の情報を探すのに手間取り、書いたアプリケーションの内容の割には、とても時間がかかりました… orz
Read the rest of this entry »