しばやん先生が Hack Azure! #4 – Synapse と Cosmos で実現するサーバーレスデータ分析 フォローアップ で紹介していますが、Synapse Analytics の Serverless SQL pool の分散クエリ処理エンジン (Distributed Query Processing Engine : DQP) については、POLARIS として、Microsoft Research から、「POLARIS: The Distributed SQL Engine in Azure Synapse」として、論文が公開されています。
論文を読むのはしんどいのですが、VLDB 2020 では、動画の公開も行われていましたので、こちらも合わせながら、ざっくりと眺めてみました。
分散クエリ処理エンジン
次の画像は、Azure Synapse Analytics Overview (r2) から引用したものとなります。
Synapse Analytics は複数の機能 / 利用形態 / 言語を用いてデータの分析を行うことができる基盤となります。

POLARIS と呼ばれている個所は上記の図の SQL と書かれている部分で使用されている分散クエリエンジンとなります。

公式のドキュメントでは、コードネームは記載されていませんが、DQP については、Synapse SQL アーキテクチャのコンポーネント で触れられています。
SQL オンデマンドの制御ノードは、分散クエリ処理 (DQP) エンジンを利用して、コンピューティング ノードで実行される小さなクエリにユーザー クエリを分割することにより、ユーザー クエリの分散実行の最適化と調整を行います。
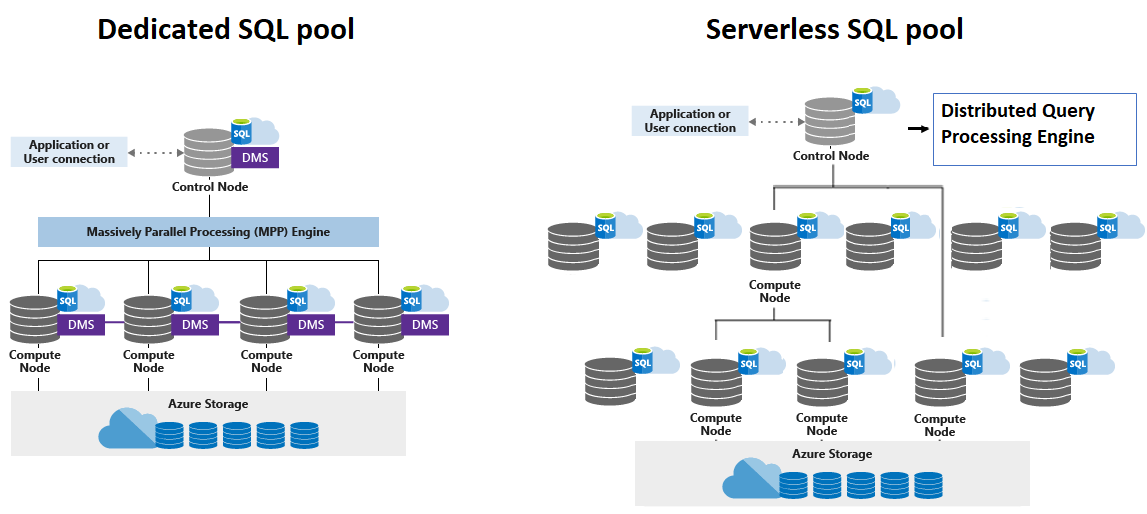
Serverless SQL pool (SQL on-demand) では、DQP により、複数のコンピューティングノードに分散させてクエリの実行が行われます。
Synapse Analytics の Serverless SQL pool では、クエリ実行時にどれだけのコンピューティングノードを使用するかを指定することはできず、何ノードを使用するかについては、コントロールノードに一任する形となっています。
料金体系としては、データ処理数による課金となっているため、何台コンピューティングノードが使用されても、操作されたデータ量に応じた課金となっています。

そのため、使用されたコンピューティングノードの台数は、料金には影響しない形態となっています。
データの抽象化
Polaris では、アクセス対象のデータを抽象化した柔軟なデータモデルとして定義することで、クエリ処理の一般化を行います。

アクセス対象のデータを、「データセル」としてハッシュパーティション / ユーザーパーティションによって論理的に抽象化を行います。このデータセルの集合を「データセット」として取り扱います。
外部の永続化ストレージに保存されたデータはデータセルとして抽象化されます。
このデータセルを、複数のコンピューティングノードに分散させてアクセスを行うことで、Data Lake に格納されているデータを複数のノードにスケールさせてクエリの処理が行われます。(結合や集計のような操作をデータの移動を伴わず、データセル内で実行できるようにしているらしいです)
メタデータ / トランザクションログを分離しステートレスなサービスで構成
上記の図の左上に記載されていますが、テーブル等のメタデータ (メタデータは、Serverless SQL Pool を使用する際に T-SQL で定義を行う各種情報になるかと思います) やトランザクションログについては、各コンピューティングノードからは分離され、Centralized Services (集中型サービス) にオフロードされています。
コンピューティングノードをはじめとした Polaris Pool 内の各種サービスはステートレスな環境として利用されることになります。
この構成の詳細については論文で触れられています。

Centralized Services についての詳細は、論文内でも触れられていないのですが、Azure SQL Database を使用した HA のような環境で構成されているそうです。(Serverless SQL Pool のデータベースは mdf/ldf ファイルが使われ構成されているようですので、SQL Server ベースの環境でメタデータの管理は行われているのだと思います)
これにより、環境に対しての変更 (障害 / スケーリング / トポロジ変更) の必要が発生した場合も、クエリ全体が影響を受けるのではなく、変更が発生した環境の部分的な影響のみで対応が可能なような構成となっているようです。
部分的な再実行によりクエリを継続できるアーキテクチャなのでしょうかね。

分散クエリオプティマイザ
Polaris では、入力されたクエリは二つのフェーズで、コンパイルが行われます。
最初に、SQL Server Cascades QO (Query Optmizer) に MEMO (logical search space : 論理検索空間) を作成します。
(MEMO については、The Cascades Framework for Query Optimization の論文辺りを参照することになりそうです。)
MEMO には、クエリを実行するためのすべての論理的に等価な代替のプランが含まれているそうです。

次のフェーズでは、分散コストベースの QO を実行して、論理プランの分散実装を列挙し、見積もりコストが最も低いものを選択し、データ移動コストも考慮に入れた、最適な分散クエリプランが実行されることになります。
データ移動コストについては、参照先の論文が「Query optimization in microsoft SQL server PDW」となっていますので、基本的な考え方については、Dedicated SQL pool のデータ移動の考え方と同じで、関連するセルを同一のコンピューティングノードで処理を実行させている形なのでしょうか。
一般的な分散クエリプランと同様に、Plaris の分散プランについても、有効非巡回グラフ (DAG) として表現が行えるようです。

Polaris の分散クエリエンジンについてはつぎのような説明が行われています。
- 分散型クエリ処理のためのビッグデータのスケールアウト技術を適用・拡張し、大規模化に向けて再構築された対話型SQLワークロード
- ビッグデータシステムにインスパイアされたクエリのタスク DAG 表現をグローバルリソースを意識した、スケジューリングとキャパシティ管理のためのマルチクエリワークロードに拡張
- インタラクティブな実行のための規模に応じたきめ細やかなタスクと依存関係のトラッキングの実現
- ビッグデータのタスク実行をより柔軟な FSA ベースのアーキテクチャに拡張しサポート (FSA が何の略なのかはよくわからず。。。)
現状、Serverless SQL pool で利用可能な DMV については、限定されており、次の DMV については参照することができます。
- sys.dm_exec_connections
- sys.dm_exec_query_stats
- sys.dm_exec_requests
- sys.dm_exec_sessions
- sys.dm_hadr_cluster
- sys.dm_hadr_database_replica_states
- sys.dm_os_host_info
sys.dm_exec_requests / sys.dm_exec_query_stats は使えるのですが、実行プラン / テキストを取得するための DMF については実行が制限されているため、実行プランの詳細については、現時点では取得する方法はありません。
分散型のクエリとして実行されていることだけは、アクセスできる情報からも確認できるようです。
SSMS で Serverless SQL pool に対してクエリを実行すると、次のようなメッセージが出力されます。
Statement ID: {E3A33CEC-2AAA-4825-BCEF-B849F10C95DF} |
Query hash: 0xD5E4DF2B21463A53 |
Distributed request ID: {7BE48A5D-31EB-4227-BA51-7EB089DA7470}.
Total size of data scanned is 2 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.
実行されたクエリの Statement ID (dist_statement_id) に対して、Distributed request ID が付与され、分散クエリとして実行されていることが確認できます。
クエリ実行時には、Total size~ のメッセージが出力されますので、この部分がクエリチューニングを行う際のポイントとなりそうですね。
クエリパフォーマンス
420 のノードで 1PB の TPC-H のデータ (parquet ファイルとして 360 TB まで圧縮が行われたデータ) でクエリを実行した結果が以下になるようです。
ペタバイトクラスのデータに対しても秒単位で結果が得られていますね。

同時実行性については、1TB の TPC-DS で5,000 のクエリを同時実行することで検証を行っているようです。
こちらも Parquet ファイルにして Azure Sotrage に格納が行われています。
安定したリソースの使用率でワークロードを完了させることができているようです。

ざっと眺めてみたのですが、英語力がないのと、DAG 周りが理解できていないので難しい。。。。