SQL Database Hyperscale については、SQL Database Hyperscale の構成や特徴を学習する で一度書きましたが、読み取りセカンダリについても追加で勉強した内容がありますので書いておこうかと。
SQL Database Hyperscale では、セカンダリレプリカの台数を 0 ~ 4 台まで指定することができます。

ハイパースケール データベースではどのような SLA が提供されるか に記載されていますが、セカンダリレプリカの台数に応じて、SLA が異なります。
- 1 台のセカンダリレプリカ : SLA 99.95%
- 2 台以上のセカンダリレプリカ : SLA 99.99%
また、セカンダリの接続ですが、読み取りワークロードのインテリジェントな負荷分散がシステムで行われるか では「ランダムに接続される」ことになっており、複数台のセカンダリレプリカをデプロイしている場合、どのレプリカに接続されるかはランダムとなるようです。
(Build 2019 の内容では、ラウンドロビンとなっていたのですが、私が検証したときにはランダムのような動作となっていました)
今回の本題はそこではなく、「プライマリレプリカで更新 / 追加されたデータがセカンダリレプリカでどのように認識されるか」という点です、
通常の SQL Database の可用性の環境については、高可用性と Microsoft Azure SQL Database で解説されています。
Basic / Standard / 汎用目的では、Azure Premium Storage をデータベースを配置するリモートストレージとして使用し、ストレージの機能を使用してデータベースのファイルの冗長性を保ち、スペアノードを用意しておくことで、SQL Server のインスタンスの障害に備えるという構成となっています。

Premium / ビジネスクリティカルでは、AlwaysOn 可用性グループの機能が使用され、複数の SQL Database のローカルディスク上のデータベースの同期をとりながら冗長性を保つという構成がとられています。
この構成については、AlwaysOn 可用性グループベースですので、セカンダリを読み取りのワークロードで使用するということができます。
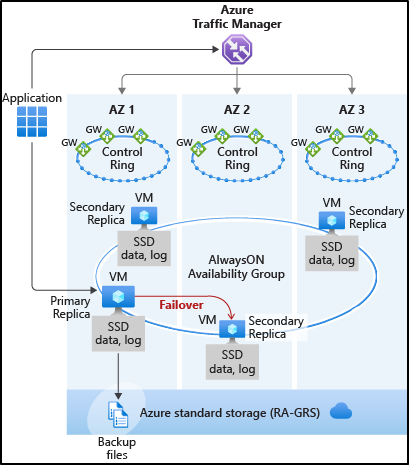
AlwaysOn 可用性グループをベースとしている場合、「プライマリで追加 / 更新された直近のホットデータ」については、セカンダリ上にキャッシュされるようになっており、セカンダリでは最新のデータがメモリ上に載っているというような動作となっています。
これは、AlwaysOn 可用性グループが「プライマリがセカンダリを / セカンダリがプライマリを認識している」構成となっており、データの同期が行われているからできる機能です。
それでは、Hyperscale ではどうなるでしょうか?
詳細については、Socrates: The New SQL Server in the Cloud で解説がされています。
全体構成の概要としては 最大 100 TB の Hyperscale サービス レベル に記載されていますが、Hyperscale は次のような構成となっています。
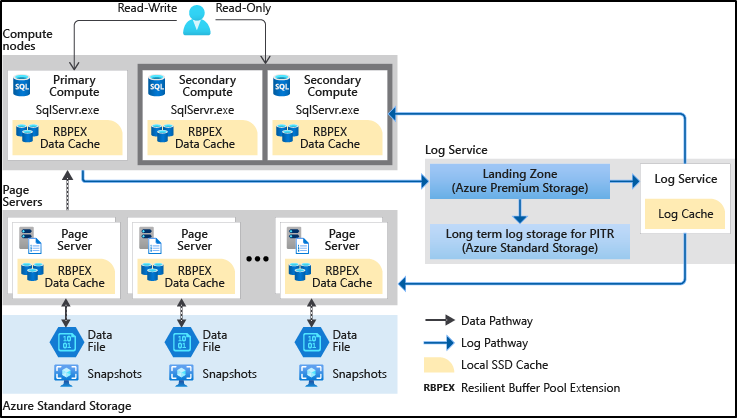
Hyperscale の特徴としては、ストレージの機能がレイヤー化され、同一のデータ領域をプライマリとセカンダリが参照する点となります。
これによって、従来のモノリシックの構成とは異なり、複数のセカンダリが存在していても、各コンピューティングノードに重複してデータを持たなくてもよくなります。
さらに、構成上の特徴の一つとして、「プライマリ / セカンダリが自分以外のノードの存在を認識していない」という点があります。
Premium でデータベースのレプリカの状態を確認してみます。
SELECT
*
FROM
sys.dm_os_performance_counters
WHERE
object_name LIKE '%Replica%'
AND
instance_name LIKE '%:%'

AlwaysOn 可用性グループでは、セカンダリレプリカのデータベースの同期を意識する必要があるため、「Availability Replica」に、データベースのレプリカを認識していることが確認できます。
同じクエリを Hyperscale に対して実行してみると、結果はありません。
つまり、AlwaysOn 可用性グループのようなデータベースレプリカは使用されていないということになります。

それでは、Hyperscale のセカンダリのデータ認識について確認してみましょう。
最初に次のクエリでデータを投入します。
DROP TABLE IF EXISTS T1 CREATE TABLE T1 (C1 char(900)) GO SET NOCOUNT ON INSERT INTO T1 VALUES(NEWID()) GO 8
データの投入が終わったら次のクエリを実行して、キャッシュの状況を確認してみます。
SELECT
DATABASEPROPERTYEX(DB_NAME(), 'Updateability') AS Updateability,
GETDATE() AS DATE,
DB_NAME(bd.database_id) AS Database_name,
OBJECT_NAME(p.object_id) AS object_name,
bd.file_id,
bd.page_id,
bd.row_count,
bd.is_modified,
pi.page_type_desc
FROM
sys.dm_os_buffer_descriptors bd WITH (NOLOCK)
LEFT JOIN
sys.allocation_units au WITH (NOLOCK)
ON
bd.allocation_unit_id = au.allocation_unit_id
LEFT JOIN
sys.partitions p WITH (NOLOCK)
ON
p.hobt_id = au.container_id
OUTER APPLY
sys.dm_db_page_info(DB_ID(), bd.file_id, bd.page_id, 'DETAILED') AS pi
WHERE
bd.database_id = DB_ID()
AND
OBJECT_SCHEMA_NAME(p.object_id) <> 'sys'
ORDER BY bd.page_id ASC
OPTION (MAXDOP 1, RECOMPILE)
取得された結果がこちらになります。

データページとして 8 行格納されているページがキャッシュされていることが確認できますね。
それでは同様のクエリをセカンダリ (ApplicationIntent=ReadOnly で接続した環境) で確認してみるとどうなるでしょうか?

プライマリで直近で追加されたホットデータはセカンダリ上でキャッシュされていないことが確認できます。
これが Hyperscale の既定の動作となります。
プライマリとセカンダリはお互いのサーバーというのを意識せず、データの同期はコンピューティングノードではなく、ログサービスによって実現されています。
通常の動作としては、ログサービスはセカンダリがキャッシュされていないデータについては、セカンダリサーバーのデータを更新 (最新化) するというような動作は行わないため、メモリ上にキャッシュされていないデータはセカンダリ上で変更はされません。
それでは、セカンダリで一度このデータを読んでみましょう。

セカンダリ上でデータがキャッシュされましたね。
それでは、プライマリでデータを更新してみます。
UPDATE T1 SET C1 = NEWID()
プライマリで更新された後にセカンダリのメモリ上のデータを確認してみます。

「is_modified」が「0→1」になったことが確認できますね。
セカンダリについてはメモリ上にキャッシュされていないデータについては、プライマリのデータの反映は行われませんが、キャッシュされているデータについてはログが適用され、最新化が行われるため、変更されたページとして認識がされます。
それでは、さらにプライマリでデータを追加してみましょう。
SET NOCOUNT ON INSERT INTO T1 VALUES(NEWID()) GO 100

これがセカンダリ上でどのように認識されるかというと、次の画像のようになります。

プライマリでは、24 ページがキャッシュされていましたが、セカンダリには 9 ページのキャッシュとなっていますね。
キャッシュしているページについてはセカンダリにログが反映された状態となりますが、実際にはページ単位ではなくエクステント (8 ページ) 単位で行われているようですね。
ページが含まれているエクステントについてログを適用するという動作になっているのではないでしょうか。
セカンダリで次のクエリを実行してみます。
SET STATISTICS IO ON GO SELECT * FROM T1
メッセージに IO 情報が出力されますが、次のような内容が出力されます。
(108 行処理されました) Table 'T1'. Scan count 1, logical reads 21, physical reads 0, page server reads 0, read-ahead reads 13, page server read-ahead reads 13, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Hyperscale では、「SET STATISTICS IO」が拡張されており、ページサーバーに対してのアクセスが確認できるようになっています。
(他にもいくつかの DMV にページサーバーのアクセスの確認用の項目が追加されています)
キャッシュされていないデータを参照した場合は、ページサーバーに対してのアクセスが発生していることが確認できますね。
Hyperscale は従来の構成と、セカンダリサーバーのキャッシュの状況が異なることがあります。
セカンダリサーバーを使用する場合、「どの状態のデータがキャッシュされている状態になっているか」ということは性能試験を行う際のポイントとなりますので、基本的な動作については覚えておくと良いのではないでしょうか。