最終更新日 : 2019/12/20
SQL Database の Hyperscale が Build 2019 で GA され、SLA 付きで使用できるようになりました。
現在公開されている情報を見ながら学習してみました。
公式のドキュメントは次の情報となります。
- 最大 100 TB の Hyperscale サービス レベル
- Azure SQL ハイパースケール データベースに関する FAQ
- ハイパースケール サービス レベル
- SQL Hyperscale のパフォーマンスのトラブルシューティング診断
より詳しい情報については、次のドキュメントから確認できます。
- Socrates: The New SQL Server in the Cloud
- Develop data application on a no-limits SQL data platform
- Introducing Azure SQL Database Hyperscale
こちらは、私が以前登壇した際の資料となります。
これらの情報を把握することで、FAQ に記載されている内容が「なぜそうなるのか?」ということを理解することができ、構成の把握を進める上で役に立つかと思います。
SQL Database との構成の違い
Hyperscale は、Azure SQL Database の一つのサービスレベルとなりますが、従来型のシングルデータベース / エラスティックプールモデルとは大きく構成が異なります。
従来型のモノリシックアーキテクチャ
従来までの SQL Database はモノリシックな DBaaS のアーキテクチャとなっていました。 
データベースに関しての全ての事象を SQL Server を実行するサーバーで管理する必要があります。
このような構成の場合、次のような要求を満たすことが難しいという問題がありました。
- サービスの柔軟性
- ワークロードに応じた柔軟な拡張と縮小
- 大規模データベースのサポート
- 稼働マシンの柔軟な変更
モノリシックアーキテクチャの構成でも、読み取りセカンダリを追加することで、読み取りワークロードをスケールアウトすることは可能です。
しかし、プライマリ / セカンダリが独自にデータを持っているため、データベースサイズに応じてセカンダリの追加に時間がかかる / 大規模なデータベースではストレージが冗長に消費されるというような課題もありました。
Hyperscale のアーキテクチャ
これらの課題に対応するため「クラウド向けの新しい OLTP のデータベースシステムのアーキテクチャ」の研究が行われ、「RDBMS の管理システムの機能を分割し、各機能を独立して展開を行う」という構成が採用されました。
このアーキテクチャについては AWS の Amazon Aurora が最初に商用として採用したものとなます。
SQL Server ベースで、この構成をとったものが「Azure SQL Database Hyperscale」です。
Hyperscale では「コンピューティングとストレージを分離する」という構成がとられており、ストレージについても「データとログを分割する」という構成が採用されています。
SQL Server が稼働しているサーバー上で、データベースのファイル (データ / ログ) が確認できますが、実際にはこれらのファイルは、リモートのサービスで提供が行われています。
(ログサービスが Amazon Aurora との違いとして挙げられることがあります)
- データファイル : ページサーバー
- ログファイル : ログサービス

これは「ストレージをスケールアウト型のマイクロサービスとして構築した」というようにも言われています。
このアーキテクチャにより、SQL Server を稼働させているサーバー自体には、永続的なデータを持たせることはなくなり、各ファイルの役割をホストしているサーバーにディスクに関しての処理をオフロードすることができるようになります。
プライマリの SQL Server からは、データベースのファイルが従来通り、存在しているように認識されます。
しかし、これらのファイルについては、I/O スタックが仮想化されており、実際のファイルを抽象化して取り扱われています。
このように、データベースエンジンの中でもストレージエンジンを抽象化したことにより、SQL Server のクエリエンジンを大幅に変更することなく (車輪の再発明をすることなく)、従来のモノリシック型のようなデータベースと同様の処理が実現できるようになっています。
Hyperscale のアーキテクチャ
それでは、Hyperscale のアーキテクチャを見ていきましょう。
Hypwerscale は次の 4 つのレイヤーで構成されます。
- コンピューティングノード
- ページサーバー
- ログサービス
- (Azure Storage)
Hyperscale では、各レイヤーはステートレスなサーバー / サービスとして変更データを受けています。
そのため、永続化 / 障害性を考慮する必要のあるデータについては、Azure Storage が使用されており、実際には、ページサーバーとサービスのバックエンドで活用されています。
本投稿では、次の構成としてみていきたいと思います。
- コンピューティングノード
- ページサーバー? + Azure Storage
- ログサービス? + Azure Storage
コンピューティングノード
コンピューティングノードの 2 種類のロール
コンピューティングノードについては、次の 2 種類のロールがあります。
- プライマリノード? (or プライマリレプリカ) : 書き込み / 読み取りの両方が可能
- セカンダリノード (or セカンダリレプリカ) : 読み取り専用
- 接続文字列に「ApplicationIntent=ReadOnly」を指定することでセカンダリに接続される。
各ノードの役割については、従来の SQL Database と同様です。
Hyperscale はマルチマスターではないため、書き込みができるノードは、プライマリノードである 1 台に限定されています。
プライマリとは、別に現時点では最大で 4 台のセカンダリを設定できるようになっており、
- 1 台のプライマリ ノード (ApplicationIntent=ReadWrite)
- 4 台のセカンダリ ノード (ApplicationIntent=ReadOnly)
の合計 5 ノードの構成が取れるようになっています。 
Hyperscale の 100TB や、4 台のセカンダリノードという構成については、現在提供されている設定としての上限となっています。
論理的には、「無制限に拡張ができる構成」となっているため、データベースサイズはセカンダリノードの上限については、今後改善される可能性があります。
実際に、Microsoft Inspire 2019 というイベントで、200TB のデータベースと 30 レプリカという構成でもデモも実施されています。 

Resilient Buffer Pool Extension (RBPEX : 回復性 or 弾性のあるバッファプール拡張)
Hyperscale のコンピューティングノードの特徴の一つに、「Resilient Buffer Pool Extension」(RBPEX) の存在があります。
SQL Server 2012 では、バッファプールからキャッシュアウトされるデータを SSD に配置するという Buffer Pool Extension (BPE) という機能が追加されました。
これを障害発生時でも回復性のあるように機能拡張したものが Hyperscale に搭載されています。
RBPEX で使用する領域には、各サーバーのローカルの SSD が使用されており、高速な I/O 性能 (<0.5ms) が期待できる領域となっています。
Hyperscale の RBPE では、Hekaton (In-Memory OLTP) のテクノロジも使用されており、高速に処理ができるような構成になっているようです。
(RBPEX のメタデータを管理するためのページテーブルに In-Memory OLTP が使用されているそうです。)
Hyperscale のアーキテクチャでは、データファイルはリモートの「ページサーバー」に存在しており、データファイルにアクセスが発生した場合は「ネットワークを介したリモートアクセス」となります。
モノリシック構成の環境では、通常、データアイルへのアクセスはローカルのパスを使用してアクセスされます。
しかし、Hyperscale ではデータベースを構成するファイルは、外部のコンポーネントとして稼働しており、データファイルへのアクセスはネットワーク経由となります。 
コンピューティングノードで今までアクセスのなかったデータへの初回のデータアクセスについては、ネットワーク経由でアクセスを行うことのオーバーヘッドは避けられません。
しかし、コンピューティングノードに RBPEX が存在していることで、2 回目以降のオーバーヘッドを抑えることができます。
通常、メモリからキャッシュアウトされると、該当のデータはデータファイルから読み込む必要があります。
RBPEX がある場合は、「一度読み取ったデータだが、メモリが不足してキャッシュアウトされたデータ」については、メモリ上からキャッシュアウトさせる際には、ローカル SSD 上に存在している RBPEX に、ウォームバッファ (ウォームデータ) としてキャッシュアウトさせる動作となります。 
再度データが必要になった場合はデータファイル (ページサーバー) から取得するのではなく、RBPEX から取得することができます。
「データファイルへのアクセスを抑制できる = ページサーバーへのネットワーク経由でのアクセスを抑制できる」ということになります。
これにより、コンピューティングノード内のデータ I/O だけでデータアクセスを完結させることができるケースが多くなります。
コンピューティングノードの RBPEX についてはすべてのデータをカバーする目的ではなく、2 次キャッシュとしての利用を目的としています。
このためコンピューティングのどの RPBEX には「Non-covering RBPEX」というような呼ばれ方もします。
(ページサーバーの RBPEX については、該当のページサーバーで担保しなくてはいけない、すべてのデータが RBPEX でカバーされます)
RBPEX は、「コンピューティングノードのメモリの 3 倍」のサイズが確保されるようになっており、これについては Hyperscale – プロビジョニング済みコンピューティング – Gen5 にも記載されています。
コンピューティングノードに搭載されている RBEPX の使用状況については、DMV から確認することができます。
SELECT * FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL)

通常、カレントの Database ID を使用した場合、自 DB のデータベースファイルの情報のみが出力されますが、Hyperscale の場合は、コンピューティングノードの RBPEX の情報も追加で出力が行われるようになっています。
RBPEX ですが、SQL Hyperscale のパフォーマンスのトラブルシューティング診断 にも記載されているように、ローカル / リモートにかかわらず、すべての RBPEXへのアクセスは 8KB 単位の I/O に変換されて実施されます。
(この I/O の傾向については SQL Server の BPEX についても同様です)
SELECT
num_of_bytes_read / num_of_reads AS read_bytes,
num_of_bytes_written / num_of_writes AS write_bytes
FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL)
WHERE file_id = 0
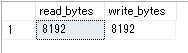
ランダム I/O であれば、8KB I/O による処理で問題ないと思いますが、大量のデータを取得するような処理の場合は、RBPEX に対して 8KB I/O 単位で処理がされるようになることのオーバーヘッドが処理時間に影響する可能性もありますので、I/O 処理の特性を意識しておくことは重要ではないでしょうか。
(ブロックサイズの大きい I/O を発生させる場合は、Synapse Analytics (旧 : SQL Data Warehouse) の方が適しているケースもありますので)
プライマリとセカンダリのデータ同期
モノリシック型のデータ同期
モノリシック型のデータベースの場合、プライマリとセカンダリが存在する場合は「セカンダリはプライマリのデータのコピー」を持つことになり、同期方法についても「同期」「非同期」のモードが選べるのが一般的ではないでしょうか。 
各サーバーががローカルのストレージを使用しており「非共有タイプのディスク」を使用し、データのコピーを行うことで、データの同期が行われます。
このタイプの場合、各サーバー (プライマリ / セカンダリ) に同容量のデータベースを保持するためのディスクが必要となります。
大規模データベースを作成する際のディスクの柔軟性が低下や、新しい読み取りレプリカを作成する際のデータベースのコピー時間がデータベースのサイズに応じて増加するというような事象が発生します。
Hyperscale のデータ同期
Hyperscale では、データベースは「非共有タイプのディスク」ではなく「共有ディスク」を使用する設計となっています。
Hyperscale では次のように、データベースのデータはプライマリ / セカンダリともに同一のページサーバーを参照する (= 共有ディスクのように同一のデータを参照 ) ようになります。
ページサーバーを共有ディスクのように使用して同一のデータファイルを参照させる仕組みですね。 
これにより、次のようなメリットを得ることができます。
- 大規模データベースに対しての柔軟なストレージ構成
- 読み取りセカンダリを追加する際に、セカンダリ用のデータコピーが不要
この構成を見ると、「同一のデータを参照」しているように見えますが、Hyperscale ではページサーバーへの書き込みは「非同期」で行われます。
そのため、プライマリとセカンダリ間では、データの変更量によってはデータの差が発生する可能性があります。
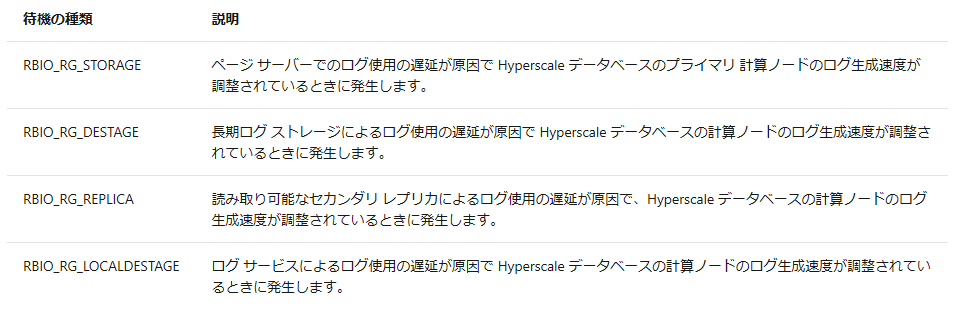
これは FAQ にも記載されており、遅延については次のように記載されています。
プライマリ計算ノードとセカンダリ計算ノードの間の遅延はどれくらいか
ログ生成速度によって異なりますが、トランザクションがプライマリ上でコミットされた時点から、すぐ、または数ミリ秒です。
Hyperscale では、FCB (File Control Block) の読み取り / 書き込みのアクセスをインターセプトし、メモリまたは RBPEX からのアクセスに変換しています。
メモリ / RBPEX に存在していないデータのアクセスについては「ページサーバー」から取得を行う必要があります。
この際、Hyperscale では「getPage(pageId, LSN) 」の関数呼び出しが発生し、指定した LSN (ログシーケンス番号) 以上、までのすべての更新を行ったページの情報をページサーバーから取得することにより、最新のデータの取得を行います。
この際、ログサービスからページサーバーへの適用にあまりにも遅延が発生していると、最新の情報がページサーバーから取得できないということが発生する可能性があります。
他にも、ページサーバーへのログの適用があまりにも遅れていると「SLA の達成に影響が出る」「セカンダリのデータとの乖離が大きくなる」というようなことも考えられます。
このようなログサービスが保持している更新ログと他のデータファイルに大きな乖離が出るような可能背のある場合は、プライマリのトランザクションログの書き込み性能を制限することで、他の環境のデータ同期の速度を調整するような動作が行われることがあります。
HA 型のデータ同期の特徴
シングルデータベースの読み取りレプリカについては「AlwaysOn 可用性グループ」の HADR の機能が使用されているため、同一のデータを保持するセカンダリの存在が保証されています。
HA 型のデータ同期の場合、セカンダリにコミットができたことにより、プライマリで発生したトランザクションをコミットさせる仕組みのため、セカンダリ側へのログレコードの反映性能がトランザクションの処理性能に影響を与えることになります。
(構成については 高可用性と Microsoft Azure SQL Database を参照してください)
また、AlwaysOn の HADR はデータベースエンジンの機能を使用しているので「各ノードがレプリカサーバーの存在を認識している」(どのサーバーに対してトランザクションログを反映させればよいかを認識している必要がある) という、各ノードが密結合な状態となります。
Hyperscale のデータ同期の特徴
Hyperscale については、AlwaysOn 可用性グループのような HADR の仕組みは使用していません。
Hyperscale は「各ノードはレプリカが存在することを認識していない」という、各ノードが疎結合な状態となっているというような構成です。
このような構成となっているため「プライマリで更新されたデータがセカンダリでもコミットされたタイミングでトランザクションが完了」するのではなく、「プライマリでデータが更新されればトランザクションが完了」となります。
続化領域として、「Azure Premium Storage」が利用されています。
そのため、1 トランザクション当たりの最小処理時間は、「5~10 ミリ秒」となっています。
(この構成は「汎用目的」のシングルデータベースと同じ構成であり、汎用目的でも 5~10 ミリ秒程度、ログの書き込みの待機時間が発生します)
「Hyperscale の読み取りレプリカは非同期モードでデータの同期が行われているため、データ更新時の反映のタイムラグが発生する」ということは覚えておいた方が良いのではないでしょうか。
可用性
Hyperscale ですが、SLA の定義は「ハイパースケール データベースではどのような SLA が提供されるか」で記載されている、次のような設定となっています。
- 既定のプライマリと 1 台の読み取り可能セカンダリ : 99.95%
- 既定のプライマリと複数台のレプリカ : 99:99%
99.95 以上の SLA を満たすためには、1 台以上のセカンダリレプリカをデプロイする必要があります。
Hyperscale では、読み取り可能なセカンダリレプリカは、0 ~ 4 台まで設定することができます。 
ページサーバー
ページサーバーは、データベースのデータファイルをホストするサーバーとなります。 
1 台のページサーバーでは、通常は「128GB」単位のデータファイルとしてふるまわれるような動作が行われます。
「コンピュートノードから見えている各データファイル毎に、1ページサーバーが存在」という構成となっているようです。
128GB / 1TB のいずれかを最大サイズとしてサポートしているようで、128 GB を超える SQL Database から移行を行った場合などは、1TB が使用されるようです。
新規に構築した環境にデータを投入していく場合は、格納したデータサイズに応じて新規にページサーバーを追加していくというような動作となり、1 データファイル (1 ページサーバー) あたりがホストするサイズは 128GB 程度に収まるかと思います。
220 GB のデータを格納するとした場合、
- 220GB の Single Database のデータベースを Hyperscale に移行 : 1 TB で 1 データファイルを作成
- 新規に作成した、Hyperscale に 220GB のデータを格納 : 最大サイズが 128GB の複数データファイルを作成
というようなデータファイルの構造となっていました。
このあたりのデータファイルの制限が、既知の制限事項 に記載されている次の記載につながります。

ページサーバーとデータファイルの関係
SQL Server のデータベースでは複数のデータファイルをサポートしています。
Azure SQL Database では、データファイルの構成は自動構成となっているため利用者が構成に関与することはできないのですが、私が検証で使用していた環境では初期は 4 つのデータファイルが存在しており、各ファイルの最大サイズは 128 GB となっていました。 
1 データファイル (1 ページサーバー) は次のような認識となっているようです。
- 最大サイズ : 128 GB
(Single Database から移行した環境は、移行前のファイルサイズによって 1TBになることもある) - 自動拡張サイズ : 10 GB
最初から 128GB のファイルを確保しているのではなく、10GB の自動拡張により増加させているような動作となっているようでした。
データベースのファイルサイズが不足すると新規にページサーバーがー追加され、SQL Server としては、128GB のファイルが追加されたように見えているようです。
実際に 250GB 程度のデータを追加した際には、データベースのファイルは次のようになっていました。
サイズが不足する直前ではなく、ある程度の余裕は持たせた状態で順次追加するというような動作となっているようですね。 
ページサーバーと Azure Storage
ページサーバーでは、Azure Storage が使用されていますが、これには、Premium Storage と Standard Storage が使用されています。
構成としては次のようになるのかと。 
データファイルの実体については安価だが低速なストレージである「Azure Standard Storage」に配置が行われています。
これとは別に RBPEX はローカル SSD 上に配置され、回復性のあるバッファプールについては高速なストレージが使用されているというような、用途に応じたストレージの使い分けが行われています。
基本的に Azure Standard Storage のファイルにはアクセスは行われず、「RBPEXだけですべてのデータがカバーされる構成」となります。
- コンピューティングノードの RBPEX : 全てのデータはカバーされない (データキャッシュの補助領域)
- ページサーバーの RBEPX : 自身がホストしなくてはいけないデータファイルのすべてのデータがカバーされる
ページサーバーの RBPEX ですが、最初ローカルとリモートのどちらに格納されているかが理解できなかったのですが、Introducing Azure SQL Database Hyperscale を読むことで、ローカル SSD キャッシュに配置され値ていることが納得できました。
このドキュメントでは次のように記載されています。
Page servers each have a standby replica online with their RBPEX cache fully populated, so they’re available to take over for the active page server in the event of failure. Again, because they’re stateless outside of cached data, a replacement can be online very quickly, without any risk of data loss.
ページサーバーが 1 台しかなく、ローカル SSD キャッシュの RBPEX 上にデータを保持しているだけでは、ページサーバーで障害が発生した場合に、Azure Standard Storage のデータを RBPEX に再ロードが発生し、復旧に大きな時間が必要となってしまいます。
このようなことにならないように、各ページサーバーには、RBPEX にフルにキャッシュを行っている状態のスタンバイレプリカがオンラインで準備されており、障害が発生した場合には即時に切り替えが行われるという構成となっています。
公開されている構成図は、ページサーバーが二つの四角で表現されているものが多いのですが、これは、スタンバイレプリカの存在を表しているようです。
データファイルのバックアップ方法
データファイルは Azure Standard Storage に格納されており、安価にストレージを利用することができる他に「データファイルのアックアップをスナップショットで対応できる」というメリットもあります。
この機能は、Box の SQL Server のデータファイルを Azure Storage に直接配置した際にも使用できる スナップショットバックアップと同様の考え方です。
従来の SQL Database ではデータベースのバックアップはスナップショットではなく、通常の SQL Server のバックアップ機能が用いられていました。
この機能を用いた場合、次のような点を考慮しておく必要がありました。
- バックアップの取得時に SQL Server の CPU リソースが消費される
- データベースのバックアップはブロック単位で取得されるため、ディスク読み取りが発生する
- データベースのサイズがバックアップ時間に与える影響が大きい
Hyperscale は 100TB をサポートすることができる環境のため、DB のバックアップによるリソースの消費や、実際に取得したバックアップを利用する際に使用する時間についても考慮をしておく必要がありました。
スナップショットを使用したバックアップとして実装することで、次のようなメリットが得られるようになっています。
- バックアップ取得時のリソース消費はストレージ側にオフロードでき、SQL Server のリソース消費に影響を与えない
- スナップショットバックアップのため、リストアも高速に実行できる
データファイルのアクセス性能
「Hyperscale はシングルデータベースで最速の環境」と思った方もいるのではないでしょうか。
(私は最初そう思っていました)
以下の画像は、SQL Database にデータベースを作成するときのポータルの画面です。 
現時点の Hyperscale は性能的には、「汎用目的とビジネスクリティカルの中間」に位置する性能になるのではないでしょうか。
(これは、選択肢として真ん中に表示されているからということではありません)
汎用目的の場合、データ / ログに対しての最大 IOPS は 7,000 IOPS であり、ディスクアクセスでは 5~10 ミリ秒の待機時間が想定されています。
ビジネスクリティカルの場合は、データ / ログに対しての最大 IOPS は 200,000 IOPS であり、ディスクアクセスは 1~2 ミリ秒の待機時間が想定されています。
Hyperscale の場合は次のようになります。
- データ : 200,000 IOPS / 1~2 ミリ秒の待機
- ログ : 7,000 IOPS / 5~10 ミリ秒の待機
データについてはビジネスクリティカルと同様、ログについては汎用目的と同様の記載になっていますね。
これは、200,000 IOPS を想定している個所についてはローカルディスク、7,000 IOPS を想定している個所はリモートストレージを利用しているためです。
ビジネスクリティカルのサービスモデルのデータベースのファイルはローカルの SSD に格納されており、高速にアクセスができるようになっています。
しかし、Hyperscale は、データファイルやログファイルはマイクロサービス化された環境をネットワークで接続した環境で実現されており、いくつかの操作ではビジネスクリティカルよりオーバーヘッドが発生します。
Hyperscale のデータアクセスだけ抜き出すと次のような構成となります。 
メモリ上にデータが載っているのであればビジネスクリティカルと変わらない性能だと思います。
それでは、メモリ上にデータが載っていない状態ではどうでしょうか?
該当のデータがコンピューティングノードの RBEX に保持されている場合は、ビジネスクリティカル相当の性能を発揮することができます。
しかし、コンピューティングノードの RBPEX に保持されていない場合はページサーバーの RBPEX にネットワーク経由で取得する必要があります。
このようなアクセスと似たようなものが汎用目的でも使用されており、ページサーバーからのデータ取得については、汎用目的相当の性能となると考えられます。
まとめると次のような形ですね。
- コンピューティングノードの RBPEX 上のデータアクセス : ビジネスクリティカル相当の性能
- ページサーバーの RBPEX 上のデータアクセス : 汎用目的相当の性能
ログサービス
それでは、最後にログサービスを見ていきましょう。
ログサービスは、デーベースのログファイルの役目を担うものとなります。 
ログサービスは内部的に複数のレイヤーで構成されています。 
ログレコードの書き込みとページサーバーへの反映
データベースに更新が行われると、Premium Storage 上の「ランディングゾーン」にログレコードが記録されます。
(現状は 1TB の Premium Storage のようですが、今後 Ultra SSD への対応も検討されているようです) 
このデータがページサーバーに連携がされることで、各セカンダリでも同様のデータを読むことができるようになります。
この処理を行っているのが「ログプロセス」となります。
この際の処理は「非同期」で行われています。 
そのため、「プライマリのデータ反映がセカンダリに適用されるのに遅延が発生する可能性がある」ということにつながっています。
ログプロセスは、ログレコードのアーカイブを長期保存するために、Standard Stoarge にログの書き込みを行い耐障害性と回復性を高めています。 
ログレコードのセカンダリへの反映
ログサービスは上記の他にも更新のレコードをセカンダリに反映する役割もあります。 
AlwaysOn の場合、この際の変更がバッファキャッシュにも適用されて直近で更新されたデータはセカンダリでもメモリ上に保持されていたはずなのですが (最近使っていないから忘れてきています…)、Hyperscale の場合は考え方が少し異なっているようで鵜s。
論文の方の記載になるのですが、現状の Hyperscale のログレコードの適用は、「キャッシュされていないページを含むログレコードは無視される」というような動作となっており、セカンダリのメモリ上に保持されていないデータの適用については行われないようです。
(検証を行った際には、ページが含まれているエクステント内の変更を検知してデータを最新化するというような動作となっているようで、該当のページのエクステント内のページは最新化が行われているようでした)
このような動作になると「直近で更新されたデータがメモリ上に保持されていない可能性がある」のではないでしょうか。
読み取りのワークロードでセカンダリを使う際には、「どのデータがメモリに乗っているのか?」という動作は意識しておくと初回読み取り性能の劣化を防ぐ一助になるのではないでしょうか。
トランザクションログの書き込み性能
シングルデータベースモデルのトランザクションログの書き込み性能
現在の SQL Database の Single Database モデルの HA のアーキテクチャでは 2 ミリ秒程度の範囲でログの遅延が発生するといわれています。
次の画像は、ビジネスクリティカルのサービスレベルをポータルからデプロイするときの表示内容となます。

1 ~ 2 ミリ秒の待機時間となっていることが確認できます。
これについては、プロビジョニングされたコンピューティング レベルの Business Critical サービス レベル にも記載があり、同様の内容となっています。

ビジネスクリティカルではデータベースは、各レプリカのローカル SSD に配置され、データの同期が行われますが、現状の構成では 1~2 ミリ秒程度の処理時間が最小でも必要となります。
トランザクションコミットのデータ同期に Azure SQL Database for Gaming Industry Workloads でも触れられています。
Gen5 + Accelerated Networking では 1ミリ秒 程度、Gen6 + NVMe + RDMA + 近接配置ゾーンを使用することで、490 マイクロ秒程度のトランザクションコミットの処理性能になると考えられており、今後の性能向上により、この最小処理時間にも変化があるようです。

Hyperscale のトランザクションログの書き込み性能
次の画像が、Hyperscale のデプロイ時に表示される性能についての記載となります。

現状の Hyperscale ではログサービスの永続化記憶域 (ランディングゾーン) には、「Azure Premium Storage」が使用されています。
Azure Premium Storage は「汎用目的」のトランザクションログの配置と同じであるため、Hyperscale と汎用目的では、現状記載されているログ書き込みのための最小書き込み時間は、実は同一の値となっています。

現状、性能の上限としては 2.5 ミリ秒程度には短縮できる可能性はあるようですが、Azure Premium Storage を使用したトランザクションログの構成の場合は、「ビジネスクリティカル」より、1 トランザクション当たりの最小処理時間を下回るということは難しいようです。
しかし、Hyperscale の今後のロードマップとして、トランザクションログのランディングゾーンを「Azure Premium Storage」から「Azure Ultra SSD ストレージ」に変更するというような検討も行われているようです。
この対応が完了すると、0.4 ミリ秒程度に処理性能が向上するようであり、これにより 1 トランザクション当たりの性能が向上します。
最後に
冒頭で紹介したドキュメントでは、さらに細かな内容が解説されているのですが、全体をざっくりと読んだ中で、Hyperscale を取り扱うに際して、最初に覚えておいた方が良い内容としてはこの辺なのかなと思いました