Managed Instance (MI) の機能アップデートですが、Feedback サイトにいくつか興味深いものが上がっており、私のセミナーの中でも紹介をさせていただいています。
Ignite で発表されたものの状況も少しきなったので、投稿時点の状況を調べてみました。
MI の機能アップデートの状況については、 REST API のプロパティにも先行で追加されているケースがありますので、こちらも併せてみておくとよさそうですね。
Read the rest of this entry »
Archive for 3月, 2019
Managed Instance の機能アップデート状況を確認してみる (2019/3/30 時点)
SQL Server 2019 CTP 2.4 がリリースされました
だいたい月次リリースで SQL Server 2019 の CTP がリリースされているのですが、2.4 がリリースされました。
まさか 3 月に 2 回 CTP がリリースされるとは…。
新機能の詳細はこちら。
データベースエンジン回りと、SSAS に機能向上が行われています。
データベースエンジン
Big Data Cluster
詳細は Release notes for big data clusters on SQL Server の CTP 2.4 の情報から。
- Big Data Cluster の GPU サポート
- Spark で TensorFlow を使用して深層学習を実行するための GPU サポートについてのガイダンスが公開されました。
Deploy a big data cluster with GPU support and run TensorFlow - ガイダンスでは AKS を GPU インスタンスを使用して構築し、そのうえで Big Data Cluster の構築を行っています。
- Big Data Cluster を使用する場合に設定するレポジトリが GPU 向けの設定となっているようです
- 外部データソースの手動作成
- CTP 2.3 までは、DataPool / Storage Pool の外部データソースが作成されていたのですが、CTP 2.4 から作成されなくなったため、手動で作成をする必要があります。
External tables - model に事前に設定しておいてあげると、新規 DB 作成時に反映されて楽かもしれませんね。
- Data Pool に対して INSERT INTO SELECT のサポート
- CTP 2.3 までは、T-SQL を使用して Data Pool に対してデータを投入する際には、「sp_data_pool_table_insert_data」というストアドプロシージャを使用していたのですが、CTP 2.4 からは、ストアドプロシージャが廃止され、INSERT INTO SELECT により、Data Pool に対してデータ収集を行う方法となったようです。
Tutorial: Ingest data into a SQL Server data pool with Transact-SQL - ある程度のまとまった行数を挿入する場合、複数の DB にレコードが分散されていました。
(テスト時は、2700~3800 行ぐらいが分散単位となっていました) - Spark のバージョンが 2.4 にバージョンアップ
- CTP 2.3 までは、Spark は 2.3.x が使用されていたのですが、2.4 が使用されるようになりました。
- 外部テーブルに対して Compute Pool の利用の制御
- 通常、外部テーブルへのアクセスについては、Master Instance から実行されます。
これを Compute Pool 経由でアクセスするように実行するオプションが追加されました - OPTION(DISABLE SCALEOUTEXECUTION)
- OPTION(FORCE SCALEOUTEXECUTION)
データベースエンジン
- 文字列の切り捨てメッセージの動作の変更
- CTP 2.3 までは、文字列長を超えて列に情報を格納する際の切り捨てメッセージの変更は TF 460 が必要でした。
- SQL Server 2016 SP2 CU6 / SQL Server 2017 CU12 でも TF 460 により使用できるようです。
- CTP 2.4 では、互換性レベル 150 では、既定で TF 460 相当の動作が行われるようになっています。
互換性レベル 150 で従来のメッセージに変更する場合は、データベーススコープの構成で、「VERBOSE_TRUNCATION_WARNINGS」により制御できます。
互換性レベル 140 以下の場合は TF 460 で制御を行うようです。
Truncation error message improved to include table and column names, and truncated value (CTP 2.1) - クエリの実行プラン取得方法の機能向上
- どちらも軽量クエリプロファイリングの使用時に、実際の実行計画に相当する情報を取得するための方法となり、軽量クエリプロファイリング v3 の一貫として追加されているようです。
Lightweight query execution statistics profiling infrastructure v3 - 拡張イベント :
query_post_execution_plan_profile の追加 - 軽量プロファイリングに基づいて取得された実行プランを、拡張イベントで収集するためには、このイベントを使用するようです。
- SQL Server 2017 CU14 でも使用できるようです。
DMV : sys.dm_exec_query_plan_stats の追加- 軽量プロファイリングに基づいて最後に実行された実際のクエリ実行プランを調べるための方法のようです。
- 使用するためにはトレースフラグ 2451 が必要となります
透過的データ暗号化 (TDE) の一時停止 / 再開のサポート- TDE を有効にするとき、中断と再開ができるようになりました。
これによりシステム負荷が高い時の TDE によるオーバーヘッドを調整できるようです。
Transparent Data Encryption (TDE) scan – suspend and resume (CTP 2.4)
SSAS
表形式モデルの多対多のリレーションシップのサポート (互換性レベル 1470 が必要)メモリ設定のリソースガバナンス
MS ブログの移転先 (2019/3/31時点)
Microsoft のシステムの刷新が行われているようで、MSDN / TechNet ブログが他の場所に移行されているようです。
日本のブログについては、TechNet フォーラム / MSDN フォーラムに移行されているパターンが多そうです。
把握できている範囲で、今後の情報取得先をまとめておこうかと。
(フォーラムについては、サポート等の用語が入っているフォーラムを抽出して、URL を機械的に生成したものですので間違っていたらすみません。。。)
SQL Server 関連で Tech Community に移行されたものについては、Welcome to the New SQL Server Blog! で対応が公開されています。
Read the rest of this entry »
Big Data Cluster のスケールアウトデータマートへのデータ投入の基本的な考え方
Big Data Cluster (BDC) はスケールアウトデータマートとしてのデータストアを持っています。
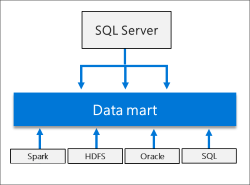
CTP 2.3 時点では、スケールアウトデータマートへのデータ投入は標準機能として、T-SQL と Spark ジョブを使用した、2 パターンが用意されています。
- チュートリアル:Transact SQL を使用した SQL Server のデータ プールにデータを取り込む
- チュートリアル:Spark ジョブの SQL Server のデータ プールにデータを取り込む
どちらのパターンでも基本的な操作方法は同じですが、少し特殊な形での利用となっていますので、まとめてみたいと思います。
Read the rest of this entry »
PySpark を使用して Big Data Cluster のストリーミング処理を書いてみる
チュートリアルで提供されているストリーミング処理はは、Scala で記述された「mssql-spark-lib-assembly-1.0.jar」なのですが、PySpark で書くとどうなるだろうと思って勉強がてら書いてみた際の内容です。
Microsoft の公式の技術文書ですと、Big Data Cluster に流用できる内容は、Azure HDInsight / Azure Databricks あたりになりますが、欲しい情報がなく、手探りでいろいろとやっていました。
Microsoft 関連のドキュメントとして、HDInsight Spark クラスターを使用して Azure SQL Database のデータを読み書きする あたりが今回の内容に近いのですが、
注意
現在、Spark から SQL Database へのデータのストリーミングは Scala と Java においてのみサポートされているので、この記事では、Spark (Scala) カーネルを使います。 SQL からの読み取りや SQL への書き込みは Python を使って行うこともできますが、この記事での一貫性を保つため、3 つの操作すべてに Scala を使います
と書かれているように、Scala を使用した例となっています。
Spark の勉強と、Python を使用した場合の情報を探すのに手間取り、書いたアプリケーションの内容の割には、とても時間がかかりました… orz
Read the rest of this entry »
Big Data Cluster のコンテナー情報の取得と整形
Big Data Cluster (BDC) は、k8s 上に複数の Pod を構築することで構成されています。
BDC の管理ポータルからも Pod の情報を取得することはできますが、kubectl 取得することで自分の必要となる情報を取得できるので、JSONPath の操作を覚えがてら、簡単なものを記述してみました。 Read the rest of this entry »
リモートデスクトップ接続時の資格情報と証明書の記憶について
Windows からリモートデスクトップで Windows Server 等に接続する場合、資格情報と証明書警告の無視を記憶しておくことができます。 

これらの情報を初期化したい場合、どの情報をクリアすればよいかをメモとして。
資格情報の記憶部分については、Connect-Mstsc – Open RDP Session with credentials のスクリプトがとても参考になります。
Read the rest of this entry »
SQL Server の OPTION(RECOMPILE)による実行プランの変化について
SQL Server では、「OPTION (RECOMPILE)」のクエリヒントを使用することで、明示的に SQL ステートメントをリコンパイルすることができます。
パラメータースニフィングにより、パラメーターを使用したクエリで、実行タイミングによって大きく件数が変わる場合などに、コンパイルによる再利用効率とのトレードオフを考慮してクエリヒントをケースが多いと思いますが、それ以外でも RECOMPILE のヒントによって動作が変更されるケースがあります。
RECOMPILE の説明には次のような記載があります。
RECOMPILE
SQL Server データベース エンジン に、クエリの新しい一時的なプランを生成し、クエリ実行完了直後にそのプランを破棄するよう指示します。 生成されたクエリ プランは、RECOMPILE ヒントを指定しないで同じクエリを実行したときにキャッシュに格納されるプランを置き換えません。 RECOMPILE を指定しない場合、データベース エンジンはクエリ プランをキャッシュして再利用します。 クエリ プランをコンパイルする場合、RECOMPILE クエリ ヒントは、クエリ内のローカル変数の現在値を使用します。 クエリがストアド プロシージャ内にある場合は、任意のパラメーターに渡された現在値を使用します。
ポイントとなるのが「クエリ プランをコンパイルする場合、RECOMPILE クエリ ヒントは、クエリ内のローカル変数の現在値を使用します。 クエリがストアド プロシージャ内にある場合は、任意のパラメーターに渡された現在値を使用します。」の個所ですね。
この辺の動作をすっかり忘れていて、処理時間に大きく影響が出たクエリを作ってしまったので、実際のクエリをベースに確認していきます。
Read the rest of this entry »
SQL Server 2017 (Windows / Linux) の Unicode テキストの BULK INSERT / bcp での取り込みについて
SQL Server では、BULK INSERT ステートメント / bcp ユーティリティ 等を使用してテキストを取り込むことができます。
SQL Server 2017 の on Windows / on Linux 両方で、これらの方法を使用することができるのですが、使用する OS によって多少動作の違いが出てきます。
これらの動作について確認する機会がありましたのでまとめておきたいと思います。
最初にざっくりとした結果を書いておきますと、
- SQL Server 2017 on Linux の BULK INSERT については、UTF-8 の取り込みができず、UTF-16 BOM あり (UTF-16 BE / UTF-16 LE) であれば可能であった
- bcp については、Windows / Linux ともに、UTF-8 / UTF-16 LE / UTF-16 BE / UTF-16LE を取り込むことができた
SQL Server 2019 CTP 2.3 で実装された高速データベース復旧で何が可能になるのか?
SQL Database では先行して実装されていた高速データベース復旧 (Accelerated Database Recovery : ADR) が、SQL Server では、2019 CTP 2.3 から使用可能となりました。
昨年の 10 月ぐらいからドキュメントは公開されていたのですが、情報を調べられていなかったので、今回の機会に調べてみました。
公式の情報としては次の内容となります。