Azure SQL Database の新しいサービスレベルである、Hyperscale が現在、Preview のサービスですが提供されています。
現時点で公式に公開されている情報としては、次のような内容でしょうか。
- Azure SQL Database ハイパースケールのパブリック プレビューのお知らせ
- 最大 100 TB のハイパースケール サービス レベル (プレビュー)
- BRK3150 – New performance and scale enhancements for Azure SQL Database
概要については、これらの情報から確認できるのですが、実際にどのようなデータアクセスが行われるのかが公開されていなかったので、可能な範囲で調べてみました。
従来までのデータベースの構成と可用性方式
従来の SQL Database では、データベースの可用性は、高可用性と Microsoft Azure SQL Database で解説されていいる 2 種類の方式がとられています。
Basic / Standard / 汎用目的のサービスレベル の方式
1 種類目が、Basic / Standard / 汎用目的のサービスレベルで使用されている、Azure BLOB ストレージの可用性を使用した方式となります。
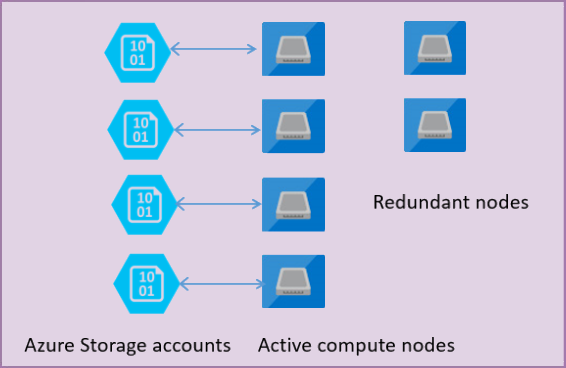
このサービスレベルでは、ストレージとコンピュートの層が完全に分離されており、Azure BLOB ストレージ上に DB のファイルを直接配置するというような方法を使用しています。
DB の可用性については、DB のレイヤーでレプリカを作成するのではなく、Azure Premium Storage 上にデータベースのファイルを配置し、ストレージの可用性の機能を用いる方法ですね。
予備ノードを用意しておき、データベースをホストしているサーバーに障害が発生した場合には、予備ノードがデータベースを参照することで、サービスを継続するという方式です。
BLOB ストレージへのデータベースの直接配置については、Box の SQL Server でも使用することができるようになっており、システムデータベース以外でしたら、Microsoft Azure 内の SQL Server データ ファイル で記載されているような方法で配置することが可能です。
下の画像は、「Standard : S0」の DB に対して、Bulk Insert でデータの挿入を行った際の、SQL Database のリソースの使用状況を Zaiba2 の仕組みを利用して、取得したものとなります。

右上のグラフは「AlwaysOn 可用性グループ」のような方法を使用して、データのレプリケーションを実施した場合に、
- プライマリとしてセカンダリにデータを送信している状況
- セカンダリとしてプライマリからデータを受信している状況
を可視化したものとなるのですが、グラフに動きがありません。
このことから、AlwaysOn 可用性グループが使われていないことが確認できます。
「HTTP Storage Usage」「Transfer Bytes」の項目にも注目してみましょう。

この二つのグラフは同一の波形を示していることが確認できますね。
「HTTP Storage Usage」は BLOB ストレージ上のファイルに対してのアクセスの発生状況を示す項目となります。
この波形と、「sys.dm_io_virtual_file_stats」で取得した、ファイルの Read / Write の両方を取得した波形が一致しています。
これらの情報から、「SQL Server のデータファイルは、BLOB ストレージ上の配置されており、SQL Server の可用性機能ではなく、ストレージの可用性機能により保護がされている」ということを類推することができます。
Premium / ビジネスクリティカル の方式
2 種類目の可用性の方式が、Premium / ビジネスクリティカルのサービスレベルで使用されている方式です。
こちらについては、AlwaysOn 可用性グループをベースとしたものが利用されています。

Premium / ビジネスクリティカルというようなサービスレベルでは、Azure BLOB ストレージにデータベースを配置するのではなく、ローカルの高速な SSD 上に直接 DB を配置するというような方法が用いられています。
この構成のノードを 4 台で 1 組とし、内部的には 4 ノードの AlwaysOn 可用性グループを構築して、DB の提供が行われます。
予備ノードは常にデータの同期が行われたアクティブな状態のノードですので、「BLOB ストレージ + 予備ノード」の構成と比較して、ノードの切り替えが高速に行うことができます。
また、AlwaysOn 可用性グループの特徴として、「待機系のノードを読み取り専用として使用することができる」というものがありますが、この構成については、このメリットを享受できることができるようになっており、現時点ではまだプレビュー中の機能ですが、アクティブ Geo レプリカを明示的に作成しなくても、基本構成のノード内のサーバーを読み取りレプリカとして使用することも可能となっています。
それではこちらも Bulk Insert を実行している最中のリソースの使用状況を見てみましょう。
今回は「Premium : P1」の情報を取得しています。

先ほどとは波形が異なっている部分が確認できるのではないでしょうか。
Standard : S0 の時は右上のグラフについては、情報が出力されていませんでしたが、今回は出力されていますね。
右上の情報は「AlwaysOn 可用性グループの複製のトラフィック」となります。
今回はプライマリで取得していますので「プライマリ→セカンダリへの複製のトラフィック」である「Bytes Sent to Replica」が発生しており、この波形につては、「file_id : 2」のトランザクションログの波形と一致していることが確認できます。
Standard : S0 では、「HTTP Storage usage」がデータベースのファイルのアクセスに応じて動いていましたが、Premium : P1 では動きが違っていますね。
このことから「ローカルのストレージに配置されたデータベースのファイルを AlwaysOn 可用性グループの機能を使用して複製している」ということが確認できます。
ここまでの 2 種類の方式のアクセスを確認してみました。
これらの方式は DTU モデル / vCore モデルの方式で使用されているものとなり、「Azure のリソースの可用性の仕組み」と「SQL Server の機能としての可用性の仕組み」を使用しながら構築されていると言えるのではないでしょうか。
Hyperscale のデータアクセスの確認
Hyperscale については、従来の DTU / vCore モデルとは大きく異なる方式が使用されています。
構成の概要としては次のようになります。
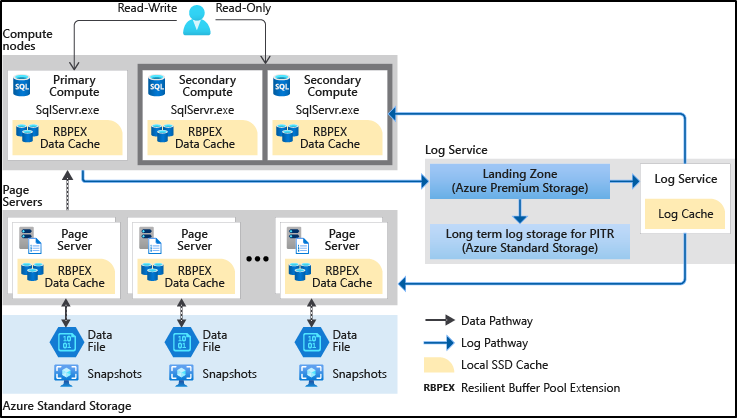
従来までのモデルは「SQL Server のデータベースの基本的な仕組み」を利用して、データベースをクラウドサービスとして提供していました。
Hyperscale については、「柔軟にスケーリングが可能な構成を Azure 上で提供できるようにするために、新しく設計された SQL Server」と言えるのではないでしょうか。
AWS の Aurora のように、クラウド時代に合わせて再設計した SQL Database が、Hyperscale になるのかと。
従来までの SQL Database では、4TB が DB の上限でしたが、Hyperscale については 100TB の DB を作成することができるようになっています。
(実際の構成としては上限は無いそうなのですが、現状は 100TB を上限としているそうです)
Hyperscale のデータベースについては、複数のレイヤーで構成されています。
- コンピュートノード
- ログサービス
- ページサーバー
- Azure Standard Storage
現状、細かな情報が公開されていないので手探りではあるのですが、興味深いのは、最大 100 TB のハイパースケール サービス レベル (プレビュー) の次の記載ではないでしょうか。
読み取り専用レプリカは同じコンピューティング コンポーネントを共有しているので、新しい読み取り可能レプリカを起動するためにデータのコピーは必要ありません。 プレビュー段階では 1 つの読み取り専用レプリカのみがサポートされます。
現状の Hyperscale には、1 台の読み取りレプリカが必ず構築されるようになっており、新しい読み取り専用レプリカを追加することができないのですが、読み取りレプリカを追加した場合に、データのコピーが行われないという記載があります。
AlwaysOn 可用性グループをベースとしたアーキテクチャでは、各サーバーが DB の実体を持つ必要があるため、読み取り専用レプリカの追加を行うためには、データベースのコピーが必要となるのですが、Hyperscale では不要と明記されています。
上記の概要を通常の DB の構成に置き換えて考えてみます。
以降の記載は、手探りで調べているものですので実際とは異なっている可能性もあります。
あらかじめご了承ください。

データベースの基本的な構成要素については、各レイヤーに分散される形になります。
データファイル

データを格納するためのデータファイルの実体については、「ページサーバー」上のローカルの SSD 上に配置されることになります。
このページサーバーでは 1 台で 1TB のデータを格納することができるようになっているようで、個々の部分が最大で 100TB (100 台) までスケールできるようです。
Hyperscale では、SQL Database のような「ストレージサイズの上限を指定する」というような概念がなく、データベースの使用領域に応じて、動的にストレージの割り当てを調整するというような仕組みがとられており、ストレージサイズの上限の明示的な指定はありません。
前述の「新しい読み取り可能レプリカを起動するためにデータのコピーは必要ありません。 」という記述がありますので、新しい読み取り専用レプリカを追加する場合は、プライマリと同様のページサーバーを参照することで、データベースのコピーを不要にしているのではないでしょうか。
ページサーバー自体は冗長化されているようではありますが、ローカルの SSD が使用されているため、最終的な永続化領域として、Azure BLOB Storage の「Standard Storage」が利用されており、ページサーバーで何らかの障害が発生した場合や、ページサーバーに存在しないデータにアクセスの必要性が発生した場合でも、最終的なデータの保存先として、使用されている Standard Storage からデータを読み取ることでカバーできるというような構成となっているようです。
バックアップについては Azure Storage のスナップショット機能を使用することで実現しており、バックアップの高速化や、バックアップの負荷によるワークロードへの影響を抑えるというようなアプローチがとられているようです。
なお、BLOB ストレージのスナップショットの利用は、Box の SQL Server でも、BLOB ストレージに直接 DB を配置している場合は、実行することができます。
ログファイル

ログファイルについての操作については「ログサービス」で実行されることになります。
プライマリに対しての更新は、ログサービスに連携され、そこから
- ページサーバーに対してのデータ反映
- セカンダリに対してのログ反映
が行われています。
セカンダリに対してのログの反映が一番詳細が見えていないところではあるのですが、変更されたデータは「ページサーバー」から読むのではなく、「セカンダリサーバー上のメモリのデータを直接変更を反映させる」というような動作をしているのでしょうかね?
ログサービス上のログファイルは、二階層で構成されており、ページサーバー / セカンダリサーバーにデータを反映させるための一時ログの領域については高速な「Premium Storage」が使用され、長期保存のためのログ領域については「Standard Storage」が使われるというような階層化された構成となっているようです。
データキャッシュ

コンピュートノードについては、クエリの実行とデータのキャッシュに使われるようで、データベースを構成するためのファイルは持たないようになっているようです。
データの参照が発生した場合、
- ページサーバーからデータを読み込み
- コンピュートノード上のバッファキャッシュにデータを格納
というような動作になっていそうです。
Hyperscale については、vCore モデルに近い、使用可能なリソースの開示が行われており、各パフォーマンスレベルで使用可能なメモリが公開されています。
メモリ上にキャッシュできないサイズのデータについては、データファイルから読み込む必要があり、ページサーバーにアクセスを行う必要がありますが、ページサーバーはリモートのリソースです。
ローカル → リモートへのアクセスのオーバーヘッドを抑えるために Hyperscale については、データのキャッシュ層をもう一段設けています。
それが、「Resilient Buffer Pool Extension」(RBPEX) です。
これは、SQL Server で実装されている バッファプール拡張 を、Hyperscale 向けに拡張した機能だと思われます。
メモリは有限のリソースですので、大量のデータにアクセスしようとした場合、メモリ上に乗らないデータが存在してきます。
通常であれば、 アクセス頻度が低いデータがキャッシュアウトされるのですが、バッファプール拡張を使用した場合は、バッファプール拡張で使用している領域上にキャッシュアウトさせることができるようになります。
これにより、データファイルより、高速なディスクをバッファプール拡張の領域として使用している場合は、データのキャッシュアウトの影響を抑えることができるようになります。
(Azure の VM の場合は、D ドライブの活用方法として、利用されることもあります)
この仕組みを発展させたものが、 Hyperscale でも使用されており、メモリ上に収まらないデータについては、コンピュートノードの RBPEX を使用して、メモリ / RBPEX に存在しないデータについてはページサーバーからアクセスを行うというような流れになるようです。
(動作を見ていると、単純なデータキャッシュアウト先として使用するというわけでもなさそうで、どういうロジックで RBPEX にデータを流しているのかがまだ把握できていません)
RBPEX のサイズについては公開されていませんが、コンピュートノードで利用可能なメモリの数倍の領域は確保されているようです。
それでは、シンプルなパターンでリソースの使用状況を見てみたいと思います。
最初にデータを Bulk Insert した際の状態です。
Hyperscale のセカンダリレプリカへのデータ反映は、AlwaysOn とは異なる仕組みが利用されていますので、AlwaysOn の複製のトラフィックは発生していません。

データ更新中に、「HTTP Storage Usage」が発生しています。
波形としては、データファイル / ログファイルの波形と近いですね。

それでは、読み取りのみのトラフィックを発生させてみます。
HTTP Storage Usage は読み取りと書き込みのトラフィックを取得していたものになるのですが、読み取りの発生時は、アクセスは行われていないですね。

このことから、HTTP Storage のアクセスについては、ログファイルのアクセスの時に発生していると考えられます。
ログファイルのアクセスの見え方については、BLOB ストレージに配置されたファイルのように見えるみたいですね。
それでは、読み取りのアクセスについてももう少し詳しく見ていきましょう。
Hyperscale のデータベースですが、「file_id」が「0, 1, 2」の 3 種類で構成が行われています。
読み取りを発生させた場合「0」「1」に対してアクセスが発生していることが確認できます。

「file_id」ですが、通常「1 : データファイル」「2 : ログファイル」となります。
「0」については一般的な SQL Server で使われることのない ID なのですが、この部分が「RBPEX」となっているのかと。
Hyperscale の場合は、次のようになるのではないでしょうか。
- file_id = 0 : ローカルの RBPEX のアクセス
- file_id = 1 : ページサーバーの RBPEX のアクセス
このような前提で先ほどのデータを見直してみます。
注目する箇所は次の場所となります。

これらのグラフは file_id 別に読み取りの IO を表示したものです。
大量のデータに対して SELECT を実行した場合、「file_id = 0, 1」の 2 箇所に対してアクセスが行われています。
ページサーバー上に存在しているデータに対しては「file_id=1」のアクセスとして認識され、ローカルの RBPEX 上に存在しているデータについては「file_id = 0」に対してのアクセスが行われていると考えられます。
その二つのアクセスの合計が、物理ページとしてのアクセスであり「Page Reads Bytes」として表れているのかと。
現在 Preview 中のサービスですので、今後のこの情報がどのように見えてくるかがわかりませんが、現時点では RBPEX の情報をある程度見ることはできるのかと。
似たようなサイズの vCore / DTU と比較して性能の特性にどのような特徴があるかは、検証が必要ですが、一般的に必要となる情報については、ある程度見ることができそうです。
Hyperscale の情報はまだ多くはありませんが、新しいアーキテクチャにより構成した SQL Database ですので、内部情報も含め、今後、公開されている情報が増えるとうれしいですね。