先日、Azure SQL Database の Hyperscale のゾーン冗長構成が一般提供開始 (GA) しました。
Hyperscale のゾーン冗長は、SQLBits 2022 付近で機能が発表され Azure SQL News Update | Data Exposed Live @SQLBits 2022 で紹介されています。
Contents
ゾーン冗長を構成した場合の性能への影響
Azure SQL Database のゾーン冗長の構成は Azure SQL Database と SQL Managed Instance の高可用性 に記載されています。
汎用目的のゾーン冗長については、スペアノードを各可用性ゾーンに配置し、vCore Premium / ビジネスクリティカルについては、可用性グループ内のノードを各可用性ゾーンに配置します。
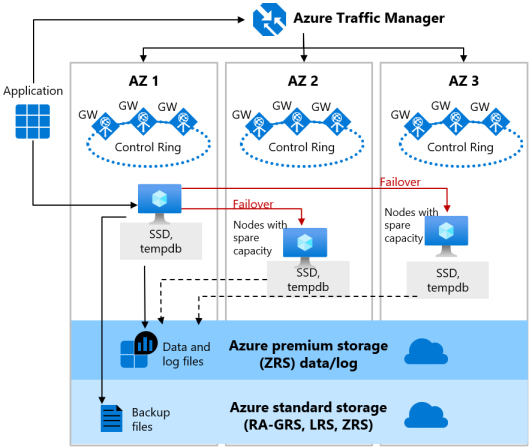

ゾーン冗長は同一リージョン内の異なるデータセンターに実行環境を配置しますので、可用性ゾーン に次のように記載されているように、通信時には 2 ミリ秒未満のネットワークパフォーマンスへの影響が発生します。
以前 Azure SQL Database の Premium / Business Critical のゾーン冗長と性能への影響 で計測をしましたが、Always On 可用性グループのテクノロジーが使用されている環境では、ローカル冗長と比較すると、ゾーン冗長を使用した場合には、1,2 ms 程度、更新系の処理に影響が発生します。
これは、Always On 可用性グループを使用している場合に避けることができないオーバーヘッドとなります。
Always On 可用性グループは同期モード / 非同期モードの 2 種類の同期方法があり、同期モードが使用された場合には、同期先のノード (セカンダリノード) でトランザクションログのコミットが行われた応答を受けてから、プライマリノードのコミットが完了します。そのため、セカンダリノードのコミットの要求を以下に高速に受けるかが重要となり、ネットワーク的な距離が遠ければ遠いほど、同期モードを使用した場合のコミットの時間に影響を与えます。
ゾーン冗長の場合は、同一ゾーン内ではありますが、異なるデータセンターという、ローカル冗長と比較して、距離的に遠いくなるため、トランザクションログのコミットに 2 ミリ秒ぐらい影響を与えることになります。
Hyperscale のゾーン冗長の構成
Hyperscale の標準的な構成については、上述の高可用性のドキュメントに次のように記載されており、標準のローカル冗長構成を使用した場合にはこの構成が取られることになります。
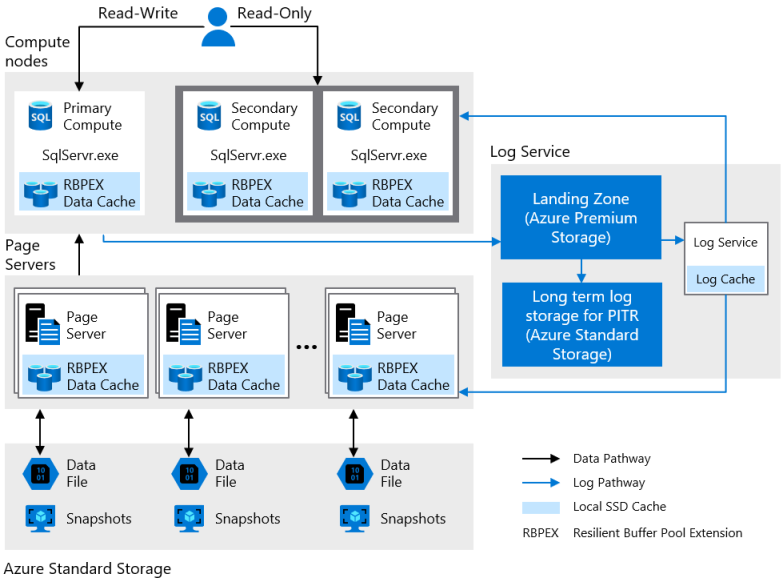
プライマリとセカンダリは同一の Log Service を使用し、データ格納領域である Page Server についても同一の領域が参照されるという構成になります。
同一データセンター内であればこのような構成が取ることができますが、ゾーン冗長のような異なるデータセンター (可用性ゾーン) にサーバーが分かれる場合にはどのような構成となるでしょうか?
Hyperscale のゾーン冗長は、
- 作成時のみ設定することが可能
- ゾーン冗長を構成する場合、リードレプリカを 1 台以上作成することが必須
- バックアップストレージはゾーン冗長または Geo ゾーン冗長を設定することが必須
となっており、他のサービスレベルのゾーン冗長とは異なる条件が追加されています。
現時点では上記のような図では明確に示されたドキュメントはないのですが、冒頭で紹介した SQLBits のセッション内で 構成について図示されたものがあります。これについては最新の情報が先日開催された Data Platform Virtual Summit 2022 の Azure SQL DB Hyperscale – What’s new and Beyond – のセッション内でも解説がされていました。
Hyperscale のゾーン冗長の構成は次のようになります。

Hyperscale をゾーン冗長で構成した場合、各ゾーンに Log Service と、Page Server のレプリカが作成され、ローカル冗長のように一つの Log Service / Page Server をレプリカのコンピューティングノードで共有するという構成ではなくなります。
Data Platform Virtual Summit 2022 のセッションはオンデマンドで質問が投げられたので、構成について確認をしたのですが、
- Q: 他ゾーンの Log Service には Always On 可用性グループのログ転送の仕組みが使われているのか?
- A: Always On 可用性グループは使用されていないが Log Service へのログブロックの転送が行われている
- Q: ゾーン冗長は 1 台以上のリードレプリカが必要だが、3 つのゾーンにコンピューティングインスタンスを作成する場合、リードレプリカを 2 台にする必要があるのか
- A: 3 つのゾーンに配置する場合には、2 台のリードレプリカを構築する必要があり、3 台構成にする必要がある
- セッションで使用されていたスライドの内容だと、ログサービス / ページサーバーは コンピューティングが 2 台の構成でも 3 つの AZ に分散されるようなので、コンピューティング以外は初期構成でも 3 AZ 構成になっているかもしれません。
ということでした。
リードレプリカの台数と可用性ゾーンの配置
Hyperscale は 当初 1 台のリードレプリカを追加している場合に、99.95 %、リードレプリカが存在しない場合に、99.9% 以上の SLA となっていました。
Hyperscale の SLA はいくつかのタイミングで変更されており、2021 年 8 月 のタイミングでは、2 台以上のレプリカで 99.99% となるようになりました。2022 年 4 月 のタイミングでリードレプリカが存在しなくても、99.99% の SLA となりました。
1 台構成でも 99.99% の SLA となりましたが、Hyperscale データベースにはどのような SLA が提供されますか? に記載されているように、1 台のレプリカを HA セカンダリレプリカとして追加することで、フェールオーバーを高速化することができ、高速な復旧を目指す場合には 1 台のレプリカを任意に追加するというような構成となっています。
ゾーン冗長の場合は、必ず 1 台のレプリカを追加する必要があり、最小で 2 台の構成が必要となります。
また、今までのゾーン冗長では、ゾーン冗長を設定するだけで 3 つのゾーンにノードが配置されるようになっていましたが、Hyperscale の場合は、必須となる 1 台のレプリカだけでは、2 つのゾーンしか使用されず、3 つのゾーンに配置するためには、2 台以上のレプリカを明示的に設定する必要があるということで、「どのゾーンに分散させるための台数にするか」を意識する必要があります。
Log Service が各可用性ゾーンに構成されることによる性能への盈虚う
各可用性ゾーンの Log Service には、ログブロックの転送が発生するということであり、性能への影響については、AlwaysOn 可用性グループベースの環境と同様の考えになるのかが気になりましたので、計測をしてみました。
単純な INSERT を実行した場合の処理時間が、次の内容となり、左がローカル冗長 / 右がゾーン冗長 (1 台のリードレプリカ) の処理結果となります。

ローカル冗長の場合、1,2 ms で処理が完了していますが、ゾーン冗長を設定した場合、2,3 ms となっており、1ms で処理を実行できるというタイミングが見当たりませんでした。ログブロックを他の可用性ゾーンに転送する処理は同期コミットで実行されているような動作になっているように見受けられました。
ゾーン冗長を設定することで 1,2ms 程度、性能への影響が発生することは意識しておいたほうがよさそうです。
まとめ
Hyperscale のゾーン冗長については、現時点では learn のドキュメントで構成図が明記されていませんが、過去に開催されたテクニカルセッションのスライドで解説されている内容が、構成を把握するための参考になります。
他ゾーンの Log Service にログブロックを送信し、そのゾーンに構築されている Hyperscale 環境でレプリカを作成するという構成になっていることを意識することで、使用する場合の挙動を把握するための参考になるのではないでしょうか。