SQL Server 2019 では SA (ソフトウェア アシュアランス : Software Assurance) の特典として、DR 用のレプリカを Azure 上に構築することがライセンスとして許容されるようになります。
(Failover servers for disaster recovery in Azure ではなく、Failover servers for disaster recovery というオンプレミスに DR を構築するパターンも新しい特典としてあります)

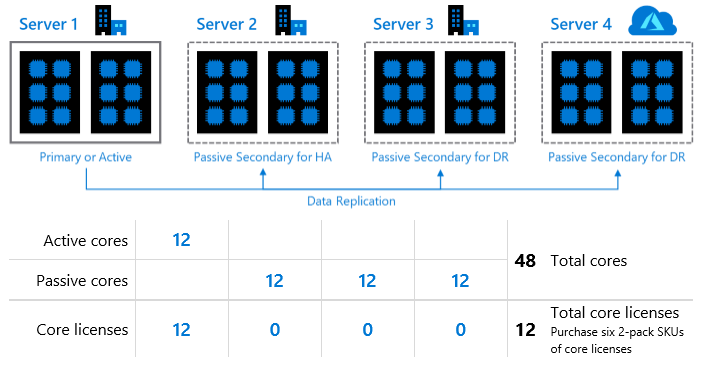
この SA 特典の詳細については、ライセンスガイド に詳細に記載されています。
従来まで、SA の特典として、プライマリのコアライセンスで、HA 用途の Passive Secondary を構築することができましたが、今回からは、新しくプライマリのコアライセンスで、DR 用途の Passive Secondary も構築ができるようになっています。

この特典ですが、「オンプレミスと Azure のどちらにも DR 環境を構築することができる」特典となっているようです。
次の図は、ライセンスガイドの P29 の図を引用したものとなりますが、プライマリのコアライセンスだけで、次のような構成も組むことが可能となるようです。
SQL Server の可用性機能としては AlwaysOn 可用性グループを構築するケースが多いですが、最新の OS (Windows Server 2019) と最新の SQL Server (SQL Server 2019) を使用した場合、どのような構成で SQL Server on Azure VM を構築することができるのか検証した一環の内容が本投稿になります。
Windows Server 2016 と SQL Server 2016 以降でも設定はできると思いますが検証はしていません。
久しぶりに Azure VM で AlwaysOn を組んだのですが、TP3 で Azure 上でワークグループクラスターを構築し、その上に CTP 2.4 のAlwaysOn を構築してみる で検証したときとは、ところどころ変わっているもんですね。
Azure 上で AG を構築する際には次のドキュメントを参照しておくと作業がスムーズに進むかと思います。
- ドメインに依存しない可用性グループを作成する
- チュートリアル:Azure SQL Server VM での可用性グループの手動構成
- Azure RM: SQL Server AlwaysOn Availability Groups Listener configuration with Azure External Load Balancer
- Azure RM: Configure a second Availability Group with a Listener using the External Load Balancer
AlwaysOn 可用性グループ (AG) ですが OS / SQL Server のバージョンの進化に合わせて機能が追加されており、いくつかのパターンで構築することができるようになっています。
代表的なものとしては次のようなパターンがあるかと思います。
(AG はこのほかにもクラスタータイプの設定 もありますので、AG の実装当初と比較して、最新バージョンでは、構成のパターンがかなり増えています)
- AlwaysOn 可用性グループ (AD を利用した一般的な構成)
- AG の各ノードを AD に参加させて構築する SQL Server 2012 からある構築パターン
- ドメインに依存しない可用性グループ (AD を利用しない可用性グループ)
- この方法はさらに 2 種類のパターンになります。
- AD に参加させるが、クラスターアクセスポイントとしては、AD のコンピューターアカウントを使用せず、DNS ベースで実施する Active Directory がデタッチされたクラスター として構築 (Windows Server 2012 R2 以降)
- AD に参加させず、ワークグループクラスターで Windows Server Failover Cluster (WSFC) と AG を構築
- この方法はさらに 2 種類のパターンになります。
- 基本的な可用性グループ (Standard Edition で構築可能な可用性グループ)
- SQL Server 2016 で追加された機能
- 機能制限はあるが Standard Edition でも利用可能な方法
- Standard Edition 以外では構築することができないため、検証には Standard Edition のメディアが必要
- 分散型可用性グループ (Distributed Availability Group : DAG)
- SQL Server 2016 で追加された機能
- 既存の AG にノードを追加するのではなく、新しく構築された AG に同期を行うことで、環境の独立性を高めて、AG を使用したデータ同期を行うことができる
今回は、投稿のタイトルにも書いたるように、AD を使用せずに構築を行いますので、「ドメインに依存しない可用性グループ」を「ワークグループクラスター」で構築したパターンを使用します。
AD を使用していないので Windows 認証ではなく、SQL Server 認証で接続することがメインとなる環境となります。
AD を使用しないことにより、認証方式の制限については把握しておいていただくとよいかと。
それでは構築のポイントを見ていきたいと思います。
使用した環境
Azure VM のイメージとしては SQL Server 2019 on Windows Server 2019 を使用して、OS 側に日本語の言語パックをインストールした状態で利用しています。(AG として冗長化するため、可用性セットを指定した構成です)
SQL Server については英語版をそのまま使用していますが、構築方法については、日本語版の SQL Server にインストールしなおした場合と大差はないはずです。
Azure VM 以外のリソースとしては次のリソースを使用しています。
- ストレージアカウント
- プライベート DNS ゾーン
- ロードバランサー
ストレージアカウント
ストレージアカウントについては、WSFC のクラウド監視 として使用しています。
Windows Server 2019 以降では、ファイル共有監視を設定する際に資格情報が指定できるようになったため、Azure Files や他の共有ディレクトリでも対応できますが、Azure で構築しているのであればストレージアカウントでよいかと。
プライベート DNS ゾーン
プライベート DNS ゾーンについては必須ではないと思いますが、名前解決を柔軟に実施させる目的のため、プライベート DNS ゾーンを作成し、Azure VM を配置している仮想ネットワークにリンクさせるようにしています。
HOSTS で名前解決するより楽ですので、DNS ゾーンは使用した方が良いかと。
作成する際のドメイン名は、Azure VM の「プライマリ DNS サフィックス」として指定するドメイン名と同一にしています。
(今回の環境であれば alwayson.local / .local ドメインを指定すると DNS ゾーン作成時に警告が出ますが、今回は AG 専用の DNS なので無視しています)

自動登録を許可しているため、Azure VM の IP については自動的に登録が行われます。

自動登録ですが、Azure VM 自身の IP を自動登録する仕組みであり、WSFC や AG のリスナーの IP については自動的には登録されません。
上記の画像の sqlvm-wsfc / ag-ln については手動で登録したものとなりますが、この辺りは構築の流れを見る際に補足していきたいと思います。
ロードバランサー
ロードバランサーは AG のリスナー (AG に接続する際のエンドポイントとなるアクセス先)? で使用します。
これは、AG を構築する際の一般的な利用方法ですね。
今回は ILB ではなく、パブリック IP を持つロードバランサーとして構築していますが、ILB でも問題はないかと。
最終的に作成したリソースが次のものとなります。
VM としては、SQLVM-01 / SQLVM-02 として作成しており、コンピューター名もこの名称になりますので、以降の記述ではこのコンピューター名を使用しています。

それでは、クラスターの構築から流れを見ていきましょう。
WSFC の構築
今回、WSFC (Windows Server Failover Clustering) はワークグループクラスターとして構築を行っています。
構築方法の詳細については、Workgroup and Multi-domain clusters in Windows Server 2016 で確認することができますので、本投稿ではポイントのみを書くようにしておきたいと思います。
LocalAccountTokenFilterPolicy のレジストリ値の設定
「各ノード」で実行します。
Azure VM の初期ログインアカウントは Administrator の名前を変更したものとなりますので、LocalAccountTokenFilterPolicy のレジストリ値は変更せずに、初期状態のまま使用しています。
Administrators グループに所属している管理者権限のユーザーで作業をする場合は、LocalAccountTokenFilterPolicy のレジストリ値を 1 に変更してください。
プライマリ DNS サフィックスの設定
「各ノード」で実行します。
WSFC に参加させる各ノードの、プライマリ DNS サフィックスに、同一の設定を行います。
今回の検証では「alwayson.local」を指定しています。

スクリプトで実行したい場合は、次のようなコマンドで実行可能です。
# プライマリ DNS サフィックスの設定 $DNSSuffix = "alwayson.local" Set-ItemProperty registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters -Name "NV Domain" -Value $DNSSuffix Restart-Computer
WSFC の構築
「各ノード」で実行します。
各ノードで、次のコマンドを実行して WSFC の機能を追加して再起動します。
# WSFC の機能の追加 Install-WindowsFeature -Name "Failover-Clustering" -IncludeManagementTools -Restart
再起動が完了すると WSFC が組めるようになりますので、次のコマンドで WSFC を構築します。
# クラスターの作成
New-Cluster -Name "SQLVM-WSFC" -Node @("SQLVM-01", "SQLVM-02") -AdministrativeAccessPoint Dns
これで、WSFC の基本部分の構築は終わるのですが、これでは色々と不足しているので手直しをしていきましょう。

コアクラスターリソースに IP アドレスを付与
「いずれかのノード」で実行します。
初期状態では、分散サーバー名のリソースには、コンピューターのリソースのみで IP アドレスは設定されていない状態となります。
通常、クライアントアクセスポイントのリソースはコンピューターと IP アドレスのセットになるのですが、今回の構成では IP は設定されていない状態が初期状態となっています。
この状態で作業を進めると、クラスタークォーラムを設定する際に、次のエラーが発生します。
Set-ClusterQuorum : ERROR CODE : 0x80131500;
NATIVE ERROR CODE : 1.
WinRM クライアントは、サーバー名を解決できないため、要求を処理できません。
コアクラスターリソースのコンピューター名に IP アドレスが割り当てられており、名前解決ができないとエラーを解消することができないため、次のコマンドを実行して、IP アドレスを設定します。
# クラスター名の名前解決のために、IP アドレスリソースを追加 (クラスター名が DNS で名前解決でき、接続ができないとクラウド監視が設定できないため)
## IP アドレスの設定
$CoreClusterGroup = Get-ClusterGroup | ? GroupType -eq "Cluster"
$ClusterIp = Add-ClusterResource -Group $CoreClusterGroup.Name -Name "Cluster IP Address" -ResourceType "IP Address"
$ClusterIp | Set-ClusterParameter -Multiple @{Network="$((Get-ClusterNetwork).Name)";Address="10.1.6.10";SubnetMask="255.255.255.0"}
$ClusterDNN = (Get-ClusterResource | ? ResourceType -eq "Distributed Network Name")
$ClusterDNN | Stop-ClusterResource
Set-ClusterResourceDependency -Resource $ClusterDNN.Name -Dependency "[$($ClusterIp.Name)]"
$ClusterDNN | Start-ClusterResource
今回、IP アドレスは「10.1.6.10 / 255.255.255.0」としていますが、IP は、VNET 内で使用していない IP アドレスを割り当てるようにして下さい。
Azure での SQL Server HADR の重要な考慮事項 に書かれているように「169.254.1.1」を設定しても問題ないはずですが、今の Azure VM は IP 固定できて、未使用な IP を特定できますので、リンクローカル IP アドレスでなくてもよいかなと個人的には思っています。
コマンドの実行が完了すると、コアリソースに IP アドレスが付与されます。

割り当てた IP アドレスは名前解決ができる必要がありますので、DNS ゾーンにも登録をしておきます。

これでクォーラムの設定を行う準備が整いましたので、クォーラム設定に移ります。
クラスタークォーラムの設定
「いずれかのノード」で実行します。
構築直後はクォーラム設定 (監視設定) がなしになっていますので、クラウド監視の設定を行います。
クラウド監視の設定を行う前に、各ノードで次のコマンドを実行し、Trusted Host の設定 をしておいてください。
(* で登録していますが、コンピューターを指定しても問題ないはずです)
# クラウド監視設定時の WinRm のため、Trusted Host 登録 (WSFC の各ノードで実行) Set-Item WSMan:\localhost\Client\TrustedHosts * -Force
これは、クォーラムの設定時に WinRM によるアクセスを各ノードで実施されるのですが、ワークグループ環境で HTTP を使用しているため、初期状態ですと次のエラーになるのを回避するためです。
Set-ClusterQuorum : ERROR CODE : 0x80131500;
NATIVE ERROR CODE : 1.
WinRM クライアントは要求を処理できません。認証スキームが Kerberos と異なる場合、またはクライアント コンピューターがドメインに参加していない場合は、 HTTPS トランスポートを使用するか、または宛先コンピューターが TrustedHosts 構成設定に追加されている必要があります。 TrustedHosts を構成するには winrm.cmd を使用します。TrustedHosts 一覧に含まれる
コンピューターは認証されていない可能性があります。 winrm help config コマンドを実行すると、詳細が表示されます。
Trusted Host の設定が行われており、PowerShell リモートによる処理が実施できるようになっていれば、次のコマンドでクラウド監視の設定ができます。
(AccountName / AccessKey は適切な BLOB ストレージの情報を設定して下さい)
# クラウド監視の設定 Get-ClusterGroup | ? State -eq "Online" | Move-ClusterGroup -Node $ENV:COMPUTERNAME Set-ClusterQuorum -CloudWitness -AccountName "ストレージアカウント" -AccessKey "ストレージアカウントアクセスキー"
Set-ClusterQuorum : ERROR CODE : 0x80131500;
NATIVE ERROR CODE : 1.
WinRM は処理を完了できません。 指定したコンピューター名が有効であること、コンピューターにネットワーク経由でアクセスできること、および WinRM サービスのファイアウォールの例外が有効になっていてこのコンピューターからアクセスできることを確認してください。 既定では、パブリック プロファイルの WinRM ファイウォールの例外によって、同一のローカル サブネット内のリモート コンピューターへのアクセスは制限
されます。
のエラーを回避するために、クォーラムの設定を行う際には、コマンドを実行するノードにコアクラスターリソースを移動してきてから、クォーラムの設定をするようにしています。
これで、クラウド監視の設定は完了です。

DNS の自動登録の無効化
「各ノード」で実行します。
これは毎回頭を悩ませる問題ではあるのですが…。
分散サーバー名は、クラスター名 (今回は SQLVM-WSFC) の IP アドレスを参照している DNS に動的登録 / 更新をすることで名前解決の正常性チェックを行うのが既定の動作となっています。
動的更新が可能な DNS を使用していない場合、クラスター名のプロパティでは、DNS 状態が、「与えられた DNS の紹介に対するレコードが見つかりません」となったり、

クラスター ネットワーク名リソース ‘クラスター名’ は、1 つ以上の関連付けられた DNS 名の登録に失敗しました。理由は次のとおりです:
No records found for given DNS query.
。
依存する IP アドレス リソースに関連付けられたネットワーク アダプターが、少なくとも 1 つの DNS サーバーにアクセスできるように構成されていることを確認してください。
というようなエラーがクラスターのイベントとして発生します。
プライベート DNS ゾーンの自動登録の設定は Azure VM の IP を自動登録設定であり、クラスターで使用されるような仮想 IP については自動登録を許可するものではありません。
DNS の自動登録の設定は、NIC の詳細設定の DNS プロパティの「この接続のアドレスを DNS に登録する」の設定状態に依存し、WSFC もこの設定が DNS 状態に影響を与えることになります。

GUI から無効にすると、Azure VM との疎通が切れ、Azrure VM の再起動をしないと再接続ができない状態になってしまいます。
これを回避するために、各ノードで次のコマンドを実行して、コマンドで設定を無効化します。
# クラスター名リソースの DNS 登録の正常性チェックを無効にするため、NIC の DNS の自動登録の無効化 (WSFC の各ノードで実行) Get-NetAdapter | ? InterfaceDescription -Like "*Hyper-V*" | Set-DnsClient -RegisterThisConnectionsAddress $false
「Set-DnsClient」で設定を変更した場合は、疎通を維持したまま設定変更が可能です。
これで、クラスター名がオンラインになった際に DNS 状態のエラーは出力されなくすることが可能です。
![]()
今回、コマンドを実行して変更していますが 1 点気を付けておきたいことは、Azure VM の NIC の設定が初期化される可能性についての考慮です。
Azure VM の NIC の MAC アドレスが変更されるような再起動が発生したケースには NIC の設定が初期化されるかもしれませんので、上記のコマンドは、「タスクスケジューラー経由でシステムの起動時などに実行されるように設定」をしておき、設定を維持し続けるようにすることが、実運用環境で必要な考慮点となります。
(DNS 状態が以上になったぐらいでは、クラスターは動作しますが、エラーは少ない方が望ましいですので)
これで、WSFC の構築は一通りできましたので、次は SQL Server 側の構成に移りましょう。
AlwaysOn 可用性グループの構築
WSFC の構築が完了したら、SQL Server 側の観点で、AlwaysOn 可用性グループの構築に移りましょう。
冒頭にも記載しましたが、今回は SQL Server 2019 on Windows Server 2019? の Developer Edition を使用しています。
このイメージでは、TCP/IP による接続も有効化されていたので、接続周りは特に設定変更しなくても問題なかったです。
セルフインストールで Developer Edition を使用する場合は、TCP/IP が有効化されているかは意識しておいた方がよろしいかと。

AlwaysOn ではノードのことをレプリカと呼ぶことがありますので、以降レプリカと書かれている場合は、各ノード (サーバー) であると考えてください。
AlwaysOn 可用性グループの有効化
「各レプリカ」で実行します。
Always On 可用性グループ機能を有効または無効にする に記載されていますが、AlwaysOn 可用性グループを有効にする必要があります。
コマンドレットで有効化がうまくできなかったので、今回は GUI から設定しています。
有効化した後は、SQL Server のサービスを再起動する必要があります。

この作業を各レプリカで実行して、SQL Server のインスタンスで AlwaysOn の機能を有効化します。
Windows Firewall の設定
「各レプリカ」で実行します。
各レプリカで使用するポートのリモートアクセスを許可しておきます。
# Windows Firewall の設定 (WSFC の各ノードで実行) New-NetFirewallRule -Name "SQL Server" -DisplayName "SQL Server" -Action Allow -Protocol tcp -LocalPort @(1433,5022,59999)
このコマンドも各レプリカで実行しておきます。
ここで、一度 OS 側の作業から、SQL Server 側の作業に移ります。
SSMS で各レプリカの master データベースに接続をして、クエリを実行しながら作業を行います。
マスターキーの作成
「各レプリカ」で実行します。
次のクエリを実行してマスターキーを作成します。
キーのパスワードはサンプルですので、適切なものを設定してください。
-- マスターキーの作成 (各レプリカで実行) CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'MASTER KEY Passw0rd'
エンドポイントの接続用ログインの設定
「各レプリカ」で実行します。
ドメイン環境の場合、SQL Server のサービスアカウントを同一のドメインユーザーに設定し、証明書を使用したエンドポイントの設定を省略するケースが多いですが、今回はワークグループ環境ですので、証明書を使用したエンドポイントの接続設定を行います。
(ワークグループでも同一のユーザー名 / パスワードのユーザーで SQL Server のサービスを実行させるという方法もありますが)
-- エンドポイントの接続用ログイン/ユーザーを作成 (各レプリカで実行)
DECLARE @password varchar(36) = (SELECT NEWID())
EXECUTE ('CREATE LOGIN AlwaysOnEndpoint WITH PASSWORD = ''' + @password + ''',CHECK_EXPIRATION=OFF')
CREATE USER AlwaysOnEndpoint FOR LOGIN AlwaysOnEndpoint
実際にパスワードを指定してログインするユーザーではありませんので、パスワードは適当なものを設定しています
(接続用ログインの作成パターンはいくつかあり、本投稿のようにプライマリとセカンダリで同一名のユーザーを使用する場合の他に、サーバーごとのユーザーを作成するパターンもあります。今回は手順が短くなる前者を使っています)
接続時に使用する証明書の設定 (プライマリ)
「プライマリ」で実行します。
(この時点ではプライマリは設定されていませんが、プライマリとして利用するレプリカで実行して下さい)
接続に使用する証明書を作成し、先ほど作成したユーザーにマッピングします。
-- エンドポイントの接続に使用する証明書にユーザーをマッピング (プライマリで実行) CREATE CERTIFICATE AlwaysOnEndpoint_Cert AUTHORIZATION AlwaysOnEndpoint WITH SUBJECT = 'AlwaysOn Endpoint',START_DATE = '01/01/2015',EXPIRY_DATE = '01/01/2100'
証明書の作成が完了したら証明書のバックアップを取得して、バックアップのファイルをセカンダリにコピーしておきます。
セカンダリはこの証明書のバックアップファイルをリストアして証明書を作成します。
-- 証明書のバックアップを取得し、2 台目のノードにコピー BACKUP CERTIFICATE AlwaysOnEndpoint_Cert TO FILE = 'D:\CertBackup\certbackup.cer' WITH PRIVATE KEY (FILE='D:\CertBackup\certbackup.pvk', ENCRYPTION BY PASSWORD='Enc Passw0rd')
接続時に使用する証明書の設定 (セカンダリ)
「セカンダリ」で実行します。
プライマリでバックアップした証明書のファイルをセカンダリにコピーしたら次のクエリを実行して、証明書を取り込みます。
-- バックアップした証明書を使用して証明書を作成 (セカンダリで実行) CREATE CERTIFICATE AlwaysOnEndpoint_Cert AUTHORIZATION AlwaysOnEndpoint FROM FILE='D:\CertBackup\certbackup.cer' WITH PRIVATE KEY (FILE='D:\CertBackup\certbackup.pvk', DECRYPTION BY PASSWORD='Enc Passw0rd')
エンドポイントの作成
「各レプリカ」で実行します。
ここまででデータ同期をする際のエンドポイントの前準備は整いましたので、実際にエンドポイントを作成するため、次のクエリを実行します。
-- エンドポイントの作成 (各レプリカで実行) CREATE ENDPOINT AlwaysOnEndpoint STATE = STARTED AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL) FOR DATABASE_MIRRORING (AUTHENTICATION = CERTIFICATE AlwaysOnEndpoint_Cert,ROLE = ALL) GRANT CONNECT ON ENDPOINT::AlwaysOnEndpoint TO AlwaysOnEndpoint
正常にエンドポイントが作成できれば、指定した TCP 5022 でポートがリスニングされた状態となっています。
Get-NetTCPConnection -LocalPort 5022

クラスターサービスアカウントの権限の補正
「各レプリカ」で実行します。
※本作業は環境固有のものである可能性があり、権限も強力なものをつける暫定的な対応です。実運用環境では、このような権限を設定しなくても、動作させることが望ましいです。
通常の流れですと、この後に可用性グループの作成を行うのですが、今回の環境では、次のようなエラーがクラスター側のログに出力されてしまい、可用性グループを作成することができませんでした。
00000c6c.00000a64::2020/01/25-06:10:46.822 INFO [RES] SQL Server Availability Group: [hadrag] Starting Health Worker Thread 00000c6c.0000238c::2020/01/25-06:10:47.339 INFO [RES] SQL Server Availability Group: [hadrag] XEvent session MSSQLSERVER is created with RolloverCount 10, MaxFileSizeInMBytes 100, and LogPath 'C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\LOG\' 00000c6c.0000238c::2020/01/25-06:10:47.340 INFO [RES] SQL Server Availability Group: [hadrag] Extended Event logging is started 00000c6c.0000238c::2020/01/25-06:10:47.340 INFO [RES] SQL Server Availability Group: [hadrag] Health worker started for instance SQLVM-01 00000c6c.0000238c::2020/01/25-06:10:47.340 INFO [RES] SQL Server Availability Group: [hadrag] Connect to SQL Server ... 00000c6c.0000238c::2020/01/25-06:10:47.343 INFO [RES] SQL Server Availability Group: [hadrag] The connection was established successfully 00000c6c.0000238c::2020/01/25-06:10:47.350 INFO [RES] SQL Server Availability Group: [hadrag] Run 'EXEC sp_server_diagnostics 10' returns following information 00000c6c.0000238c::2020/01/25-06:10:47.350 ERR [RES] SQL Server Availability Group: [hadrag] ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297) 00000c6c.0000238c::2020/01/25-06:10:47.350 ERR [RES] SQL Server Availability Group: [hadrag] Failed to run diagnostics command. See previous log for error message 00000c6c.0000238c::2020/01/25-06:10:47.350 INFO [RES] SQL Server Availability Group: [hadrag] Disconnect from SQL Server
可用性グループのクラスターリソースが SQL Server との疎通を想定通りに完了できていないために発生しているため、権限の補正を行っておきます。
-- AG のクラスターリソースからのアクセス用に権限を付与 (各レプリカで実行) ALTER SERVER ROLE [sysadmin] ADD MEMBER [NT AUTHORITY\SYSTEM]
最小限の権限を調査する時間がなく、SYSTEM に sysadmin 権限を付与していますが、動作させることを優先するのであれば、これで上記のエラーは回避できます。
自分の検証環境に一から構築した SQL Server 2019 を使用した場合は、この問題は発生しませんでしたので、SQL Server on Azure VM 固有かもしれません。
可用性グループの作成
「プライマリ」で実行します。
今回は AGDB01 というデータベースを追加しますので、事前に次のクエリでデータベースを作成しておきます。
CREATE DATABASE AGDB01 BACKUP DATABASE AGDB01 TO DISK=N'NUL'
DB の作成が完了したら、次のクエリを実行して、可用性グループを作成します。
-- 可用性グループの作成 (プライマリで実行)
CREATE AVAILABILITY GROUP [AG01]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY,
DB_FAILOVER = ON,
DTC_SUPPORT = PER_DB,
CLUSTER_TYPE = WSFC,
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0)
FOR DATABASE [AGDB01]
REPLICA ON
N'SQLVM-01' WITH (
ENDPOINT_URL = N'TCP://SQLVM-01.alwayson.local:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SESSION_TIMEOUT = 10,
BACKUP_PRIORITY = 50,
SEEDING_MODE = AUTOMATIC,
PRIMARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_LIST = ('SQLVM-02', 'SQLVM-01'),
READ_WRITE_ROUTING_URL = 'TCP://SQLVM-01.alwayson.local:1433'
),
SECONDARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_URL = 'TCP://SQLVM-01.alwayson.local:1433'
)
)
,N'SQLVM-02' WITH (
ENDPOINT_URL = N'TCP://SQLVM-02.alwayson.local:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SESSION_TIMEOUT = 10,
BACKUP_PRIORITY = 50,
SEEDING_MODE = AUTOMATIC,
PRIMARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_LIST = ('SQLVM-01', 'SQLVM-02'),
READ_WRITE_ROUTING_URL = 'TCP://SQLVM-02.alwayson.local:1433'
),
SECONDARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_URL = 'TCP://SQLVM-02.alwayson.local:1433'
)
)
GO
これで、AG が作成されます。


可用性グループの参加
「セカンダリ」で実行します。
セカンダリで次のクエリを実行して、可用性グループに参加させます。
-- 可用性グループの参加 (セカンダリで実行) ALTER AVAILABILITY GROUP [AG01] JOIN
自動シード処理の有効化
「各レプリカ」で実行します。
AG の初期同期の方法はいくつかありますが、今回は自動シード処理によりデータベースの初期同期を実施しますので、各レプリカで次のクエリを実行します。
-- 自動シード処理の有効化 (各レプリカで実行) ALTER AVAILABILITY GROUP AG01 GRANT CREATE ANY DATABASE
これにより、セカンダリでデータベースの自動的な復元が行われ、可用性グループのデータ同期の設定が完了します。
リスナー経由で接続するための Azure 側の設定
今回は Azure 上に作成していますので、ロードバランサー経由で可用性グループのリスナーに接続させる必要があります。
Azure のロードバランサーの設定は次のドキュメントを参照してください。
外部のネットワークからアクセスする場合、各 Azure VM のネットワークセキュリティグループで 1433 に対しての接続を許可しておく必要がありますので、注意点はそれぐらいかと。
基本は上記のドキュメントを見ながらロードバランサーを作成すれば問題ありません。
ドキュメントには 58888 の負荷分散規則も記述されていますが、可用性グループだけであれば 59999 だけで問題ありません。
リスナーの作成
「プライマリ」で実行します。
最後の作業としてプライマリで可用性グループのリスナーを作成する作業を行います。
最初に次のクエリを実行して、未使用の IP でリスナーを作成します。
-- リスナーの作成 (プライマリで実行) ALTER AVAILABILITY GROUP [AG01] ADD LISTENER N'AG-LN' ( WITH IP((N'10.1.6.11', N'255.255.255.0')) , PORT=1433)
次に PowerShell で次のコマンドを実行して、リスナーの IP アドレスリソースの IP 変更と、ロードバランサーからのプローブポートの設定を行います。
# リスナーの IP アドレスに Probe Port を設定
$AGIP = Get-ClusterResource -Name "AG01*" | ? ResourceType -eq "IP Address"
$AGIP | Set-ClusterParameter -Multiple @{OverrideAddressMatch=0;Address="ロードバランサー IP";SubnetMask="255.255.255.255";ProbePort=59999}
Get-ClusterGroup -Name "AG01" | Stop-ClusterGroup
Get-ClusterGroup -Name "AG01" | Start-ClusterGroup
これで一通りの作業は完了です。
ここまでの作業で可用性グループとして、正常な状態で稼働している環境が構築できています。

作業を進める中で、いくつかの作業では設定の不足によりエラーが発生しましたが、WSFC と AlwaysOn 可用性グループの構成を理解できていれば解決できる問題が多かったかと思います。
できる限り PaaS を使用したいですが、AlwaysOn 可用性グループを構築せざるを得ない場合は、AD を使用しない環境で構築ができると、構成の簡素化が行うことができ、かなり利便性が高いと思います。
AD が必要な場合も Azure Active Directory Domain Services を使用することで、対応できるケースもあるかもしれませんが、最新の OS や SQL Server を組み合わせることで、そもそもとして AD を使わなくても環境構築ができるケースもありますので、本投稿のような構築パターンも覚えておくと良いのではないでしょうか。
[…] https://blog.engineer-memo.com/2020/01/25/azure-vm-%e3%81%a7-ad-%e3%82%92%e4%bd%bf%e7%94%a8%e3%81%97… […]
【後で読みたい!】Azure VM で AD を使用しない AlwaysOn 可用性グループを Windows Server 2019 と SQL Server 2019 で構築する | Tak's Bar
5 2月 20 at 23:22